



中国人民大学高瓴人工智能学院李崇轩、文继荣教授领衔的团队与蚂蚁集团携手合作,共同完成了这项研究工作。其中,游泽彬和聂燊二位博士研究生系李崇轩副教授的弟子,就读于中国人民大学高瓴人工智能学院。该研究依托于团队先前发布的成果,即首个性能可与LLaMA 3相媲美的8B参数扩散大语言模型——LLaDA。
本次,研究团队将LLaDA技术应用于多模态领域,成功推出了LLaDA-V——一款融合了视觉指令微调的纯扩散多模态大型语言模型(MLLM)。这一成果标志着对目前以自回归为核心的多模态技术的一次重大进展,同时也揭示了扩散模型在多模态理解方面的广阔前景。
近年来,在图像、音频、视频等多种输入模态的处理上,多模态大语言模型(MLLMs)实现了显著的进步。不过,目前多数方法都依赖于自回归模型。尽管有研究尝试将扩散模型融入 MLLMs,但常常采用自回归与扩散相结合的混合架构,或者受到语言建模能力的限制,结果往往不尽如人意。
在LLaDA成功展示扩散模型在纯语言任务上与自回归模型(例如LLaMA3-8B)相媲美的能力之后,一个核心问题随即浮现:扩散语言模型是否也能在多模态任务中展现出与自回归模型相仿的表现?LLaDA-V正是对这一疑问给出了有力的解答。
研究团队以 LLaDA 为语言基础,引入了视觉编码器(SigLIP 2)以及 MLP 连接器,将视觉信息映射至语言嵌入的领域,成功实现了多模态数据的精准对齐。在 LLaDA-V 的训练与采样过程中,均采用了离散扩散策略,从而超越了传统的自回归模式。
团队预计近期开源训练推理代码以及 LLaDA-V 权重。
性能亮点

数据可扩展性强,多项基准表现优异
大规模实验结果显示,LLaDA-V展现出诸多引人瞩目的特性:
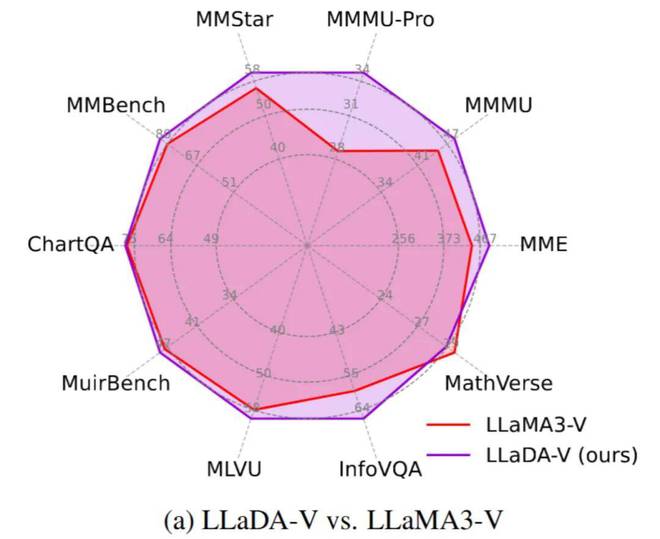
该团队对LLaDA-V进行了评估,并与其基于LLaMA3-8B构建的自回归基线LLaMA3-V进行了比较,尽管两者在其他方面保持一致。
结果显示,LLaDA-V 在数据可扩展性方面表现更为出色,尤其在涉及多学科知识(例如MMMU)的基准测试中。值得注意的是,尽管LLaDA-8B在纯文本任务上略逊于LLaMA3-8B,但LLaDA-V在11个多模态任务中却超越了LLaMA3-V。这一事实表明,扩散架构在处理多模态任务时具有一定的优势。
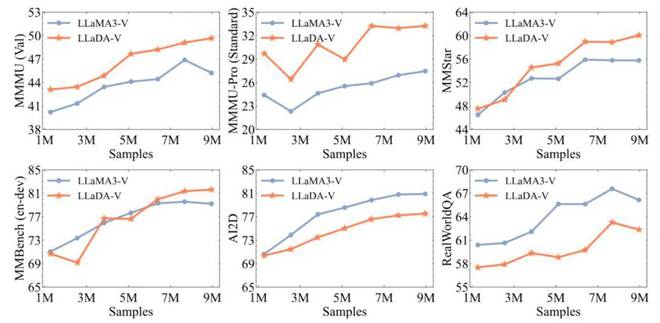
在纯扩散与混合架构领域,LLaDA-V模型在多模态理解任务上实现了业界领先水平,超越了现有的混合自回归-扩散模型,如metaMorph和Show-o,以及纯扩散模型。这一成就充分展示了依托于高效语言扩散模型的MLLM架构在性能上的优越性。
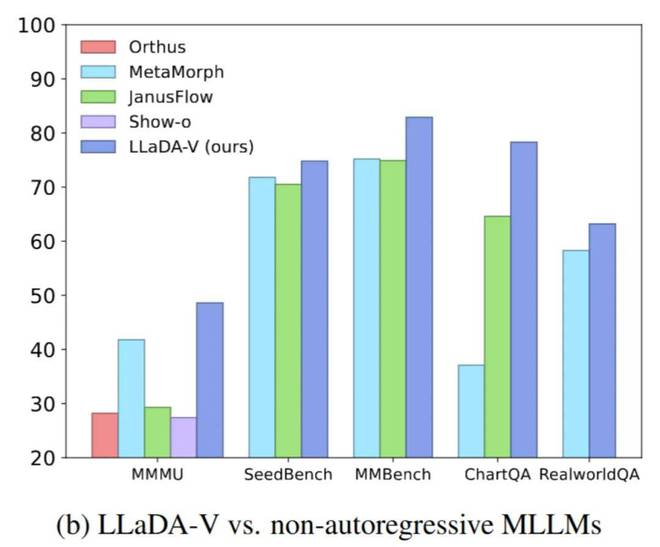
尽管LLaDA在语言能力上与Qwen2-7B存在明显差距,然而LLaDA-V在多个基准测试中,例如MMStar,成功缩小了与Qwen2-VL这一强大模型的性能差异,二者性能水平相当(分别为60.1和60.7)。这一成果进一步证实了扩散模型在多模态领域的巨大潜力。
下图是 LLaDA-V 同用户进行交流的场景。

LLaDA-V生动地描绘了一幅宁静且层次丰富的瑞士阿尔卑斯山景:一条绿意盎然的小径曲折向前,行人沿着小径缓缓前行;在远处,山谷中可见一座白色的教堂,周围环绕着轻柔的雾气,高耸入云的群山显得雄伟壮观;蓝天白云的点缀,使得整个画面显得更加宁静祥和,整体布局清晰,意境深远。
核心方法
LLaDA-V 的核心特点在于融合了视觉指令微调框架以及 LLaDA 的掩码扩散技术。具体来说,下方的图表详细描绘了 LLaDA-V 的训练与推理步骤。
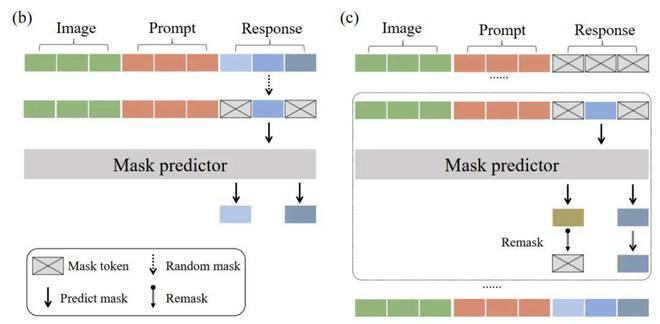
本系统采用了一种经典的「视觉编码器、MLP 投影器与语言模型」架构设计。其中,视觉编码器(SigLIP 2)负责从图像中提取关键特征;随后,MLP 投影器将这些特征映射至 LLaDA 的嵌入空间;而 LLaDA 语言塔则承担了处理融合后的多模态输入并生成相应回复的任务。尤其值得注意的是,LLaDA-V模型引入了双向注意力机制,这一机制使得模型在预测过程中能够全面把握对话的上下文信息,这一优势在消融实验中得到了验证,结果显示其性能略胜于对话因果注意力机制。
训练目标上,LLaDA-V在LLaDA的基础上进行了拓展,旨在实现多轮和多模态对话的支持。其核心理念在于,在训练过程中,维持图像特征和用户提示不变,而对模型的输出内容进行随机遮蔽。具体来说,训练目标仅针对被遮蔽的部分计算交叉熵损失。
推理分析显示,LLaDA-V的生成机制并非基于自回归的逐词预测,而是依托于扩散模型的逆向去噪步骤。这一过程始于一个完全被遮蔽的回复,随后模型在多个阶段中循环预测被遮蔽的词汇单元,并逐步重建出完整的回复内容。研究引入了LLaDA的低置信度重遮蔽策略,优先保留置信度较高的预测结果,从而有效提升了生成文本的质量。
总结与展望
LLaDA-V成功融合了视觉指令微调和掩码扩散模型,这一成果证实了扩散模型不仅在语言任务上能够与自回归模型相媲美,而且在多模态理解领域也显现出其强大的竞争力与显著优势,特别是在数据扩展性方面。
这项工作不仅为 MLLM 的发展拓展了新的技术途径,同时也对多模态智能技术依赖自回归模型的传统理念提出了挑战。伴随着语言扩散模型技术的持续进步,我们有充分的理由预见,基于扩散技术的 MLLM 在未来将承担更为关键的角色,并进一步拓宽多模态人工智能的边界。





