


麦吉尔大学团队 投稿
量子位 | 公众号 QbitAI
当前的数据合成技术存在一定缺陷,主要体现在合理性与数据分布的一致性上,并且不具备自动调整以适应不同数据类型的能力,其扩展性也不够理想。
大型语言模型由于受到采样效率的限制以及上下文窗口规模的制约,很难直接构建出大规模的数据集。
构建出结构匹配、数据统计可靠且语义准确的模型输出,已经成为一个迫切需要解决的课题。
为此,麦吉尔大学团队提出了新方法LLMSynthor——
运用此技术,可将大型模型转变为具备结构识别能力的数据模拟器,并在涉及隐私保护及数据匮乏的场合,生成既保密又高质量的替代数据。
LLMSynthor:让LLM变成“结构感知的生成器”
在众多应用场景中,诸如人口统计、电子商务、出行等领域,数据的敏感性问题使得共享变得尤为困难,同时,针对不同格式的数据,还需单独开发模型,这不仅增加了成本,也降低了模型的迁移能力。
传统手段,诸如贝叶斯网络、生成对抗网络(GAN)等,在构建高维度的依赖关系时存在困难,同时它们在泛化能力上表现不佳,且稳定性不足,而且常常产出诸如“九岁博士”这类看似符合统计数据却缺乏实际意义的样本。
近期,大模型技术同样被应用于数据生产领域,然而,这一应用面临诸多挑战,包括采样速度较慢、数据分布难以控制以及上下文信息的局限性,这些问题使得高效构建结构完整的大规模数据集变得困难。
LLMSynthor的解决方案是:它让语言模型不再直接生成数据,而是转变为一种“结构感知的生成器”,并借助统计对齐反馈机制,不断进行迭代和优化。
整体框架如下:
Step 1:结构推理
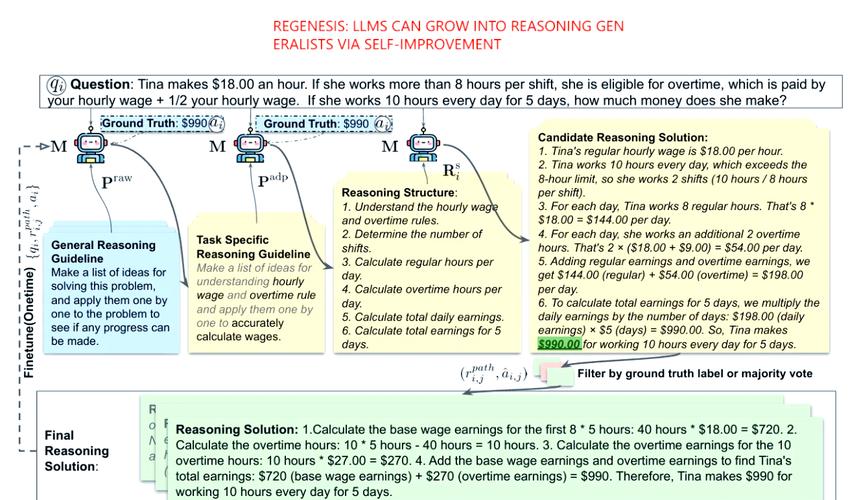
生成可信数据,关键是理解变量之间的依赖结构。
尽管Copula模型能够将变量分布与关系建模进行分离,但在处理高维和多语义的复杂场景时,其扩展性存在一定局限。
LLMSynthor的核心突破在于:它采用大型语言模型来模仿Copula的功能。
LLM可以被看作是现实世界中联合分布的一种高维先验,在其预训练阶段,它已经将人类行为和社会结构的变量共现规律融入其中。
通过对统计摘要的深入理解,例如频率和分布等方面的认识,它能够推断出变量之间复杂的关系,同时还能借助语义信息来发掘那些未被察觉的依赖性。
Step 2:统计对齐
LLMSynthor并非直接将原始数据与合成数据进行对照,而是借助统计摘要手段(例如变量分布、联合频率等)来评估真实数据与合成数据之间的差异程度。
这样,就既保留了结构信息,又避免泄露个体数据。
由于仅依靠统计数据特征,即便输入的是汇总的指标数据,依然能够产出结构完善且语义相符的模拟数据,这种特性尤其适用于人口普查、问卷调查等对隐私保护要求较高的场合。
此外,LLMSynthor的校准机制具有可追溯性,它不仅能够评估“整体上的偏差”,而且还能精确指出这些偏差是由哪些变量或变量组合引起的。
这种细致入微的反馈可以直接应用于下一轮的生成结构调整,从而逐步实现内容的对齐。
Step 3:生成分布而不是样本
传统方法逐条生成样本,效率低且难控分布。
LLMSynthor被调整为输出一系列可选取的分布模式(即建议),例如:“一位25岁的女性,身处一线城市,对美妆产品有购买需求”,随后进行大规模的采样操作。此外,该系统还能进一步调用图像等外部生成工具,以实现跨模态任务的拓展。
该提议在统计反馈与LLM常识的双重指导下,能够有效规避诸如“10岁博士”等不合逻辑的变量搭配。
此方法不仅运作效率高、架构稳固可靠,而且能够借助“分布式描述性语言”来促进不同模型的协作生成,进而达成跨模态、多渠道、多目标的数据合成与仿真。
Step 4:迭代对齐
经过反复运用“结构推断、数据统计对比、规则构建以及新数据样本采集”这一流程,模型最终能够构建出一个在结构上和统计数据上都与实际数据极为相似,同时亦合乎常理的合成数据集。
理论保障
除了经验效果,LLMSynthor还具备理论收敛保障。
LLMSynthor团队提出了局部结构一致性定理,即:在合理的假设条件下,若某个变量或变量组的分布初始存在一定的偏差,那么通过有限的迭代次数,可以将这种偏差导致的误差收敛到任意一个可接受的范围内。
这表明LLMSynthor并非仅仅凭借直觉接近,而是基于数学原理,稳步地趋向于真实的数据结构。
多场景实测
为了测试LLMSynthor的实际应用效果和系统运行的可靠性,研究者在三个具有典型意义的实际应用领域展开了实验,这些领域涵盖了电子商务交易、人口数据分析和城市交通出行。
电商交易生成
这是一个包含连续与离散变量的混合场景,变量关系复杂。
作者运用贝叶斯网络技术,构建了一个具有明确结构的可控数据集,该数据集旨在对建模能力进行评估。
实验数据表明,LLMSynthor在边缘分布误差以及联合分布误差方面均展现出卓越的表现,能够精确地复现变量之间的依赖关系。
进一步的实验预测表明,该模型通过合成数据训练后,在处理真实数据时表现最为出色,充分展现了其强大的实用价值。
人口微观合成
人口数据中家庭与个人之间存在着嵌套关系,其结构天然呈现非结构化特征。此类数据在诸如城市规划、政策评估以及资源配置等众多关键领域得到广泛应用。LMSynthor能够有效处理这种复杂的嵌套结构,并且在包括老年贫困率在内的16项政策指标中,相较于现有方法表现出了显著的优越性。
城市出行模拟
出行信息涵盖了时间序列、地理位置以及行为等多重复杂要素,这些构成了交通模拟和应急处理的重要依据。
LLMSynthor依托于多源数据,已成功创造出与都市生活节奏相契合的模拟路径。尤为重要的是,它能够根据提示指令进行轨迹生成的响应。
例如,当东京巨蛋于晚上8点举办演唱会时,合成数据能够呈现该时段的人流波动情况,同时彰显了其还原现实场景和操控场景的能力,这些特性使其非常适合用于政策模拟和事件预先演练。
大模型兼容情况
LLMSynthor具有高效生成能力,无需经过训练,并且能够与多种大型模型相兼容。即便更换为Qwen-2.5-7B等开源模型,也能保持稳定运行。此外,它还展现了出色的扩展性和良好的落地适配性能。





