


GPU已成为推动高性能计算(HPC)任务加速的流行选择,其应用范围广泛,涵盖人工智能以及科学仿真等多个领域。尽管如此,目前学术界进行的多数微架构研究,依旧以15年前设计的GPU核心流水线为研究对象。
本文通过逆向工程深入分析了现代英伟达GPU的核心架构,详细阐述了其设计中的核心要素。同时,文章还阐释了GPU如何借助硬件与编译器的协同作用,在执行任务时由编译器来主导硬件的操作。具体来说,研究揭示了指令发射逻辑的运作原理,涵盖了发射调度器的策略、寄存器文件及其关联缓存的结构,以及内存流水线的众多特性。此外,对基于流缓冲区的指令预取器进行了分析,探讨了其与现代英伟达GPU的兼容性及潜在的应用前景。同时,对寄存器文件缓存以及寄存器文件读端口的数量进行了深入研究,以评估其对模拟准确度及性能的潜在影响。
我们对这些新发现的微架构细节进行了建模,这一做法使得我们的模型在执行周期的平均绝对百分比误差(MAPE)较之先前的高级模拟器有所下降,降幅达到18.24%。与此同时,与英伟达RTX A6000这样的实际硬件相比,我们的模型在平均绝对百分比误差上仅为13.98%。值得一提的是,我们还验证了这一新模型同样适用于英伟达的其他架构,例如图灵架构。
最终的研究成果显示,现代英伟达GPU所采用的软件依赖性管理策略,在性能与芯片面积两大关键指标上,相较于传统依赖硬件计分板的方案,表现更为出色。
引言
近年来,GPU不仅在图形处理领域得到了广泛应用,而且在处理通用任务时也颇受欢迎。其架构设计赋予了GPU强大的并行处理能力,这使得诸如生物信息学、物理学以及化学等众多现代领域都能借助这一特性。目前,GPU已成为推动现代机器学习任务加速的关键工具,而这些任务对内存带宽和计算能力的要求尤为严格。在最近几年,GPU的微观结构设计、NVlink互连技术以及NCCL通信框架均实现了显著的突破。这些成就极大地促进了大型语言模型的推理与训练效率,而这通常要求使用由数千个GPU组成的集群系统。
然而,关于现代商用GPU微架构设计的公开资料较为稀缺,目前学术界的研究普遍以2006年发布的特斯拉微架构作为研究基础。然而,自特斯拉架构问世以来,GPU架构经历了显著演变,因此,以该架构为依据的研究模型可能会造成研究结果的偏差。本研究的目的是阐明现代英伟达GPU架构中各组成部分的独特属性和具体细节,以此增强学术领域对微架构模型的精确度。文中阐述的模型与细节,有助于研究者更深入地把握提升下一代GPU所面临的挑战与潜在机会。概括而言,本文的主要贡献包括:
本文后续内容结构安排如下:第二节阐述了该研究的背景及动因;第三节详细阐述了我方所采用的逆向工程技术;第四节对现代英伟达GPU架构中的控制位及其具体行为进行了描述;第五节介绍了这些GPU的核心微观结构;第六节说明了我们在模拟器中构建的模型特性;第七节对所建模型与实际硬件的准确性进行了评估,并与Accel-sim模拟器进行了对比,分析了指令预取流缓冲区的作用,探讨了寄存器文件缓存及寄存器文件读端口数量对性能的影响,对比了不同的依赖管理策略,并讨论了该模型对其他英伟达架构的适用性;第八节回顾了相关的前期研究;最终,第九节总结了本研究的核心成果。
背景和动机
学术领域内,关于 GPU 微架构的研究普遍以 GPGPU-Sim 模拟器为工具,该工具所采用的微架构模式受到广泛关注。近期,该模拟器进行了升级,引入了自 Volta 架构以来子核心(即英伟达所说的处理块)的相关技术。图 1 中详细展示了模拟器所构建的架构框图。该结构包含四个子核心以及若干共享部件,例如L1指令缓存、L1数据缓存、共同内存以及纹理处理单元。
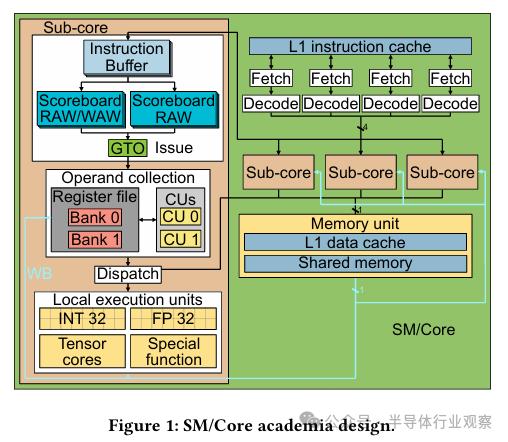
在 GPU 流水线的取指环节,循环调度器会挑选出位于 L1 指令缓存内的下一条指令,同时确保指令缓冲区尚有空余的槽位。这些缓冲区是针对每个线程束专门设置的,它们的作用是存放线程束中提取和解析完毕的连续指令。指令将保留在此缓冲区中,直至它们准备就绪并被选中进行发射。
在发射过程中,GTO调度器将挑选一个线程束执行指令发射任务,前提是此线程束并未处于等待屏障状态,并且其最古老的指令与流水线内其他正在运行的指令之间不存在任何数据依赖。过往的研究曾提出,每个线程束配备有两个计分板用于检测数据依赖情况。第一个计分板负责记录对寄存器的待写操作,从而能够追踪写后写(WAW)和写后读(RAW)依赖问题。一旦计分板上的所有操作数均被清除,指令方可发射。此计分板负责记录活跃消费者的数量,旨在防范读后写(WAR)风险。之所以需要第二个计分板,是因为即便指令按序发射,其操作数仍可能发生乱序,这种现象尤其在可变延迟指令(如内存指令)中较为常见。发射之后,这些指令将被依次排列,并且存在一种可能性,即在较年轻的算术指令将结果写入之前,它们会读取其源操作数。若前述指令的源操作数与后者的目标操作数相吻合,便可能引发读后写风险。
一旦指令被发出,便会被置于一个收集单元(CU)之中,静候直至获取到所有源寄存器的操作数。每个子核心都配备有专属的寄存器文件,该文件由多个存储体组成,每个存储体设有数个端口,从而使得在单个周期内能够以较低的成本进行多次访问。仲裁器则负责解决对同一存储体出现的多个请求可能引发的冲突问题。一旦指令的所有输入操作数均已在收集单元中备齐,该指令便进入分发环节;在此环节中,它将被分配至相应的执行单元,例如内存单元、单精度单元或特殊功能单元;执行单元的处理延迟将根据其类型及指令的具体要求而有所不同。当指令抵达写回阶段后,计算结果将被记录到寄存器文件中。
Accel-sim所构建的GPU微架构与基于2006年推出的特斯拉架构的英伟达GPU相仿,并融入了若干现代特性。这些特性主要包括子核心模型以及运用IPOLY索引的扇区缓存,其设计灵感源自Volta架构。尽管如此,该架构仍缺少一些现代英伟达GPU所具备的关键组件,例如L0指令缓存和统一寄存器文件。此外,子核心的若干关键部件,诸如发射控制逻辑、寄存器数据集或其缓存机制等,尚未进行升级以适应现有的设计方案。
本项任务致力于对英伟达现代GPU核心的微观结构进行逆向研究,并对Accel-sim模拟器进行升级,以整合新发现的特性。如此一来,Accel-sim模拟器的使用者将能从更贴近业界在商业设计中所验证的成功基准点出发,进而提升他们工作的相关性。
逆向工程方法
本节内容详细阐述了我们所采用的研究手段,这些手段旨在揭示英伟达安培架构GPU核心(SMs)的微观结构设计。
我们的研究方法依托于构建包含少量指令的小型基准测试程序,并记录特定指令序列的运行时长。我们通过在代码区域周边运用指令,将 GPU 的时钟计数器成功保存至寄存器,并存储于主内存中,以便后续处理,以此获取经过的周期数。所评估的指令序列一般由人工编写的 SASS 指令及其控制位构成。针对不同的测试类型,我们将对记录的周期数进行可视化处理,以此来验证或推翻有关控制位含义或微架构中特定功能的假设。
下面给出两个示例来说明这种方法:

尽管英伟达并未提供官方的编写SASS代码(即英伟达汇编语言)的工具,然而众多第三方软件使得开发者能够对汇编指令进行重新排序和调整(这包括对控制位的操作)。比如,当编译器输出的代码并非最佳时,这些软件便能够用来提升关键内核的运行效率。MaxAS 作为首个专门用于编辑 SASS 二进制文件的工具问世,紧接着,针对 Kepler 架构,我们又开发了其他辅助工具,例如 KeplerAS。随后,TuringAS 和 CUAssembler 也相继诞生,旨在为更先进的架构提供支持。鉴于 CUAssembler 在灵活性、扩展性以及最新硬件兼容性方面的优势,我们最终选择了它。
现代英伟达 GPU 架构中的控制位
现代英伟达GPU的指令集架构(ISA)中,包括了控制位以及编译器所提供用以保证正确性的信息。与此前的GPU架构不同,后者是通过在运行时追踪寄存器的读写操作来验证数据依赖性,而当前的这些GPU架构则是依赖于编译器来处理寄存器之间的数据依赖关系。为此,汇编指令中均设有若干控制位,这些位不仅有助于提升性能和减少能耗,而且还承担着管理依赖关系的重任。
以下内容详细说明了指令中所包含控制位的各项功能。依据相关文档进行阐述,然而这些文档往往表述模糊或信息不全。鉴于此,我们采纳了第三章节中所述的方法,以揭示这些控制位的含义,并对其是否按照以下描述的方式运作进行核实。
每个周期,子核心能够发出一条指令。在常规情况下,一旦线程束程序序列中的最旧指令准备就绪,发射调度器便会尝试向该线程束发送指令。编译器通过控制位来标识指令何时达到发射条件。若在上一周期发射指令的线程束中,最旧的指令尚未准备好,发射逻辑将依照5.1小节所述的策略,从其他线程束中挑选一条指令进行发射。
为了解决固定延迟指令在生产者与消费者之间的依赖问题,每个线程束配备了一个特定的计数器,即所谓的停顿计数器。只有当该计数器的数值不为零时,该线程束才不具备发射指令的资格。编译器在设置该计数器时,会考虑指令产生的延迟,并据此减去生产者与首个消费者之间所发出的指令数量。这些线程束的每个停顿计数器在每个周期都会减去1,直至降至0值。发射逻辑仅会检视该计数器,并且只有当其数值为0时,才会考虑对同一线程束执行下一条指令。
一条指令,其延迟时长为4个周期,且首个消费者为后续指令的加法操作,在停顿计数器中被记录为4。依据第三部分所述方法,我们已证实,若停顿计数器配置有误,程序输出将出现错误,这是因为硬件不会对RAW风险进行检测,而是直接依赖于编译器设定的这些计数器。另外,该机制在占用面积和能耗布线方面展现出一定的优势。需知,相较于传统的计分板技术,我们无需将固定延迟单元直接连接至依赖的处理模块,布线环节可以省略。
存在一个名为Yield的控制位,它的作用是告知硬件在接下来的周期内不应发出属于同一束线的指令。只有当子核心中的其他线程束在下一个周期均未做好发射准备时,才会选择不发射任何指令。
每个指令都配备了停顿计数器和Yield位。当停顿计数器的数值超过1时,线程束将不可避免地至少经历一个周期的停顿。在此情形下,即便Yield位被设定,线程束仍将进行停顿。
此外,某些指令(例如内存操作指令、特定功能指令)存在不固定的执行延迟,导致编译器无法预知其具体耗时。故而,编译器难以仅凭暂停计数器来应对此类潜在风险。此类风险可通过依赖计数器位得到有效缓解。每个线程束配备了六个专用的寄存器用于存储这些计数器,标记为SBx,其中x的取值范围在0至5之间。每个计数器能够记录的最大数值为63。
线程束启动之际,相关计数器均被设定为零。在生产者完成数据发送操作后,会提升一个特定计数器的数值,而当数据被写入时,该计数器则相应减少。消费者需遵循指示,唯有当计数器值降至零时,方可继续执行。
针对WAR的负面影响,其作用原理与其它情况相仿,所不同之处仅在于计数器的减量动作是在指令读取源操作数之后进行,而非在数据被写回内存时发生。
指令中包含特定控制位,这些位的作用是标识发射阶段可能增加的两个计数器的最大值。其中,一个计数器在数据写回操作中会相应减少,主要用于解决RAW和WAW依赖问题;而另一个计数器则在寄存器被读取时减少,旨在处理WAR依赖。为了实现这一功能,每条指令都设有两个3位的字段,分别用于指示这两个计数器的上限。此外,每条指令都配备了一个六位数的掩码,该掩码的作用是明确指出指令需检查哪些依赖计数器,以判断其是否已经准备好执行发射任务。值得注意的是,一条指令在执行过程中,最多能够对六个计数器进行全面检查。
若一条指令涉及多个源操作数,并且其生产者存在可变延迟,那么这些生产者可以共享一个依赖计数器,而不会影响到并行性。然而,当存在超过六个消费者指令,且这些指令对应的生产者具有不同的可变延迟时,这种机制可能会导致并行性受到限制。在此情形下,编译器需在两个方案之间作出抉择以处理此类问题:一是将众多指令归类于同一依赖计数器之下;二是调整指令的排列顺序,采取新的排列方式。
在发射生产者指令之后,依赖计数器的提升是在随后的周期中进行的,故而其效果需待一个周期之后方能显现。所以,若消费者紧随其后成为下一条指令,生产者需将暂停计数器设定为2,如此一来,才能防止在下一个周期中触发消费者指令的发射。
在图 2 中,我们可以找到处理具有可变延迟特性的生产者依赖关系的示例。该代码演示了四条指令,其中三条是加载指令,一条是加法指令,以及它们对应的编码。鉴于加法指令与加载指令(即具有可变延迟的指令)之间存在依赖关系,因此采用了依赖计数器来避免数据损坏的情况发生。指令位于PC地址0x80的指令与位于地址0x50及0x60的指令之间形成了RAW(Read After Write)依赖。因此,当指令0x50和0x60被发出时,SB3的数量会增加,而在执行写回操作时,其数量会相应减少。此外,加法指令与位于地址0x60和0x70的指令之间则存在WAR(Write After Read)依赖关系。因此,当执行指令0x60和0x70时,SB0的值会上升,随后在读取它们对应的寄存器源操作数之后,该值会相应减少。最终,在执行加法指令前,依赖计数器的掩码编码要求SB0和SB3的值必须为0。指令0x70继续依赖SB4来管理RAW/WAR对后续指令的危害,然而,指令0x80无需等待这一依赖计数器的完成,因为其与加载指令间不存在任何依赖联系。在完成源操作数的读取后,及时清除WAR依赖是一项关键的优化措施,尤其是考虑到源操作数在许多情况下会比结果生成时间提前很多,尤其是在处理内存相关指令时。在此例中,指令0x80需等待指令0x70完成对R2的读取并消除WAR依赖,而非等待指令0x70执行写回,后者可能要在数百个周期后才会进行。
验证这些计数器是否准备就绪的另一种途径是使用DEPBAR.LE命令。比如,输入DEPBAR.LE SB1, 0x3, {4,3,2}这一指令,意味着只有当依赖计数器SB1的数值不超过3时,程序才能继续运行。该指令的最后一个参数(例如:[, {4,3,2}])为可选项,一旦启用,在目标ID(此处为4、3、2)的依赖计数器归零之前,该指令将无法执行。
DEPBAR.LE 在特定情境下极为实用。比如,当消费者需等待一系列N个依次写回的可变延迟指令(诸如带有STRONG.SM修饰符的内存指令)的前M条时,它能够让这一系列指令共享一个依赖计数器。采用 DEPBAR.LE 并将参数调整为 N-M,该指令将暂停,直到序列中的前 M 条指令执行完毕。另一个应用场景是,通过复用同一依赖计数器,可以有效防范 RAW/WAW 和 WAR 类型的风险。若某条指令对两种不同类型的威胁共享同一依赖计数器,鉴于 WAR 威胁的处理通常先于 RAW/WAW 威胁,因此 DEPBAR.LE SBx, 0x1 将会持续等待,直至 WAR 威胁被彻底解决。之后,线程束得以继续运行。而任何后续依赖该结果的指令,也必须等待,直至该依赖计数器降至零,这标志着相关结果已被成功写入。
此外,GPU通过运用寄存器文件缓存技术来有效降低能耗,并缓解寄存器文件读端口的竞争现象。这种技术由软件进行管理,具体做法是:每条指令的源操作数中包含一个控制标记(称作重用位),该标记指示硬件是否应对该寄存器的内容进行缓存。有关寄存器文件缓存的具体组织架构,请参阅第5.3.1节的相关内容。
最后需指出,尽管本文主要探讨NVIDIA的架构,然而通过分析AMD的GPU指令集文档,我们能够发现,AMD也采纳了硬件与软件相结合的设计理念,以协调依赖关系并增强性能表现。与NVIDIA的DEPBAR.LE指令相似,AMD采用了waitcnt指令——这一指令依据不同的架构版本,为每个wavefront(即warp)配备了3至4个专门的计数器,而这些计数器则与特定的指令类型相对应,旨在防止由这些指令引发的数据冲突。AMD规定,常规指令不能通过控制位直接进行计数器归零的等待,而是需要明确地加入waitcnt指令,这样做会使得指令的总数有所增加。尽管这种设计减少了解码时的成本,但同时也使得整体的指令数量有所增长。相较之下,NVIDIA的方案展现出两个显著优势:首先,每个warp可使用的计数器数量比其他方案多出两个,总计达到六个;其次,这些计数器并未与特定的指令类型固定关联,这便使得在同一指令类型内部,能够更有效地进行依赖链的并行管理。值得注意的是,在RDNA 3/3.5架构中,AMD采纳了DELAY_ALU指令以减轻ALU指令依赖造成的流水线停滞问题。这一指令的一大亮点是,它可以在不依赖编译器的情况下,有效规避ALU指令间的数据冲突。相比之下,NVIDIA的做法是依靠编译器来为固定延迟指令准确设定Stall计数器。虽然这种方法能够减少指令总数,但同时也带来了解码成本的上升。
GPU 核心微架构
在本节内容里,我们依照第 3 节所述的阐释方式,对现代商用英伟达 GPU 核心微架构的研究成果进行阐述。图 3 中呈现了 GPU 核心微架构的关键组成部分。接下来,我们将对指令发射调度器、前端处理单元、寄存器存储模块以及内存流水线部分的微架构进行逐一详述。
指令发射调度器
在本部分内容里,我们将深入探讨现代英伟达GPU的指令发射调度机制。首先,我们将在(1)小节中阐述在每一个周期内,哪些线程束被认定为指令发射的潜在对象。接着,在(2)小节中,我们将详细讲解其选择的具体策略。
(1)线程束就绪条件
在指定的时间段内,只要符合特定要求,该线程束将被认定为发出最早指令的潜在对象。这些要求中,部分与该线程束自身的先前指令相关,而其余部分则与处理器整体的状态紧密相连。
显而易见的一个条件是,指令缓冲区中须有有效的指令存在。此外,还需确保线程束中最古老的指令与该线程束内尚未完成的更早指令之间,不存在任何数据依赖上的风险。这种指令间的依赖性,是通过第4节所述的控制位,并借助软件的支持来进行处理的。
除此之外,只有当确认在指令被发出并进入执行阶段时,所有必要的资源都已准备就绪,线程束才可能被认定为在指定周期内发射其最早指令的潜在对象。
这些资源中包括执行单元,该单元配备了一个输入锁存器。当指令进入执行阶段,该锁存器必须保持空置状态。若执行单元的宽度是线程束的一半,则该锁存器将占用两个周期;而若宽度为完整的线程束,则仅需一个周期。
针对常量缓存中包含源操作数的指令,发射阶段会执行标签检索。若所选线程束中最新指令所需操作数需从常量缓存中提取,但该操作数并未存于缓存内,调度器将暂停指令的发射,直至缓存缺失问题得到妥善解决。但若四个周期后缓存缺失问题仍未得到解决,调度器将转而切换至另一线程束(即拥有待执行指令的最年轻线程束)。

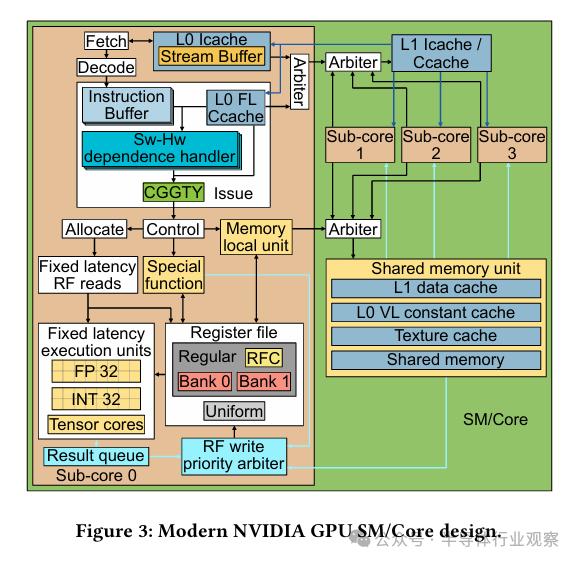
关于寄存器文件读端口的可用性,指令发射调度器并不清楚所评估的指令在后续周期中是否拥有充足的端口进行读取,从而避免出现停滞。经过观察,我们发现,在清单1中,若移除最后一条FFMA指令与最后一条CLOCK指令之间的NOP指令,代码中的冲突便不会导致第二条CLOCK指令的发射出现停滞,由此我们得出了上述结论。通过众多实验,我们旨在阐明指令发射与执行间的流水线布局,遗憾的是,并未发现一个能全面契合所有实验数据的理想模型。然而,所阐述的模型在绝大多数情况下均能适用,因此我们决定采纳这一模型。在该模型中,指令在从发射到读取源操作数的过渡阶段,存在着两个额外的中间步骤,且这些指令的延迟是固定的。该阶段被称作控制阶段,无论是固定延迟指令还是可变延迟指令,都必须经历这一环节。在此阶段,主要任务是提升依赖计数器的数值,或在必要时查阅时钟计数器的具体数值。实验结果显示,要使计数器的增加得以实现,在执行增加计数指令与等待依赖计数器归零指令之间,必须间隔至少一个周期。因此,连续执行这两条指令时,不能依赖计数器来规避数据依赖的风险。然而,若第一条指令设置了Yield位,或者停顿计数器的值超过1,则可例外。
在固定延迟指令的第二个阶段,会进行寄存器文件读端口的可用性检查,指令执行将暂停于此,直至确认端口能够安全使用,避免发生端口冲突。这一阶段我们称之为分配阶段。若需了解寄存器文件读写流水线及其缓存的相关详细信息,请参阅第5.3小节。可变延迟指令,如内存指令,在完成控制阶段操作后,会跳过分配阶段,直接进入一个队列。只有当队列中的指令确保不会产生任何冲突,它们才能被准许进入寄存器文件,并继续在读取流水线中进行处理。在寄存器文件端口的分配过程中,固定延迟指令的优先级高于可变延迟指令。这是因为,正如前文所述,依赖关系的处理由软件负责,而固定延迟指令必须在发射之后,在确定的周期数内完成,以确保代码的准确性。
(2)调度策略
为了研究指令发射调度器的运作策略,我们精心构建了一系列测试案例,这些案例涵盖了多个线程束的复杂交互。在记录每个时钟周期内,指令发射调度器所选择的特定线程束时,我们收集了相关信息。这些数据是通过记录 GPU 当前时钟周期的指令来获取的。不过,由于硬件限制,无法连续发射两条此类指令,因此我们在它们之间插入了若干其他指令,通常是空操作指令(NOP)。我们还改变了 Yield 和停顿计数器控制位的具体值。
实验数据表明,线程束调度器遵循GTO策略进行操作,一旦同一线程束内的指令符合既定条件,便会优先执行该线程束的指令。而在转换至另一线程束时,则会挑选出符合条件且年龄最小的线程束进行调度。
图4展示了该指令发射调度器策略的实验效果。图中展示了在同一子核心内运行四个线程束时,三种不同指令发射模式的对比。这些线程束执行的是相同的程序代码,该代码由32条指令构成,每条指令都能在每个时钟周期独立发射。
在第一种情形(如图4a所示)里,所有的暂停计数器、依赖掩码以及Yield位均被调整为零值。调度器便从最年轻的线程束W3着手,依次发射指令,直至在指令缓存(Icache)中遭遇空缺。由于缓存出现空缺,W3未能获取到有效指令,于是调度器不得不转而向W2发射指令。W2 在 Icache 中成功匹配,这得益于它对 W3 所携带指令的复用。当 W2 运行至 W3 指令缺失的节点时,该缺失问题已被妥善解决。同时,所有后续指令均已在 Icache 中定位。因此,GTO 调度器得以连续发射该线程束的指令直至完成。随后,调度器持续向W3(最年轻的线程束)发送指令直至完成,鉴于此时所有指令均已存放在Icache中。紧接着,调度器转而控制W1,从起始至终依次发出指令,最终对W0(最老的线程束)采取同样的处理方式。
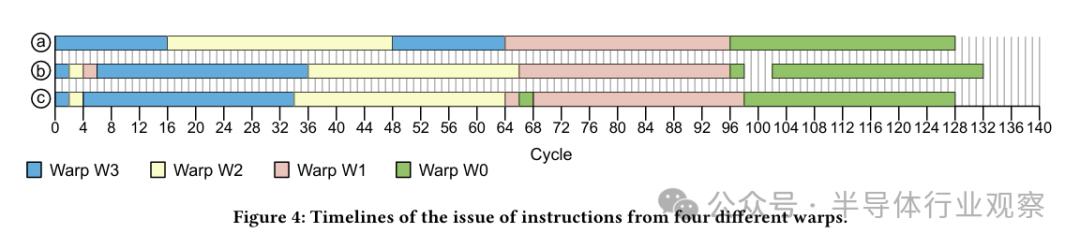
图 4b 展示了指令发射的时间线,其中每个线程束的第二条指令将停顿计数器设定为 4。观察可见,调度器在经过两个周期后,由 W3 转向 W2,再经过两个周期,又切换至 W1,继而在两个周期后返回至 W3(由于 W3 的停顿计数器归零)。当 W3、W2 和 W1 完成执行后,调度器便开始从 W0 发射指令。在执行W0的第二道指令之后,调度器成功创建了四个空闲时段,这是由于没有其他线程束能够有效遮蔽由停顿计数器引发的延迟。
图 4c 中呈现了线程束在执行第二条指令并设置 Yield 位后,调度器所采取的动作。观察可知,调度器在完成每个线程束的第二条指令发射后,会转而调度至其他线程束中最为年轻的那个。以 W3 转至 W2,以及 W2 再转回 W3 为例。我们对配置了Yield位且未发现额外线程束的情况进行了测试(图中内容未呈现),发现调度器会进入一段时间的空闲状态。
我们称这种指令发射调度器策略为CGGTY,该名称源于编译器通过操控位(包括停顿计数器、Yield位以及依赖计数器)来辅助调度器进行操作。
然而,我们仅在同一个线程块(CTA)内的线程束中观察到了这一现象,这是因为我们尚未成功研发出一种能够有效分析不同线程块之间线程束相互作用的可靠方法。
前端
通过查阅英伟达的多份文档中的图表,我们可以了解到流多处理器(SM)由四个子核心组成,线程束按照循环模式平均分配在这些子核心上(即通过warp ID除以4的余数)。每个子核心都配备了一个专有的L0指令缓存,并且该缓存与SM内所有四个子核心共用的L1指令缓存相连接。此外,我们假定有一个仲裁机制来应对来自不同子核心的众多请求。
每个L0指令缓存都配备了一个指令预取器。实验结果验证了Cao等人之前的研究成果,该研究指出指令预取在GPU中确实起到了积极作用。尽管我们未能明确英伟达GPU所采用的预取设计细节,但我们推测其可能是一种较为简单的机制,例如通过流缓冲区在缓存缺失时预取连续的内存块。经过深入分析,我们设定了流缓冲区的容量为16,对此内容将在后续部分进行详尽的阐述。
实验中我们未能明确界定获取指令的具体方法,然而可以肯定的是,这种方法与指令发射的策略相仿;若非如此,在指令缓冲区中难以找到有效指令的情况应当较为常见,然而在实验过程中,我们并未遇到此类现象。因此,我们推测,每个子核心在每个周期内均能获取并解析一条指令。取指调度器会尽力从与之前周期(或最新发出指令的周期)所发指令相同的线程束中提取指令,但前提是它未发现指令缓冲区中已存指令数与当前正在搜集的指令数之和已达到缓冲区的容量上限。
在此情形下,系统将转向指令缓冲区中尚有空闲位置的最新线程束。我们假定每个线程束的指令缓冲区包含三个条目,这一设定基于从取指至发射涉及两个流水线阶段,以此确保贪心策略的有效性。然而,若指令缓冲区仅容纳两个条目,则指令发射调度器的贪心策略将无法奏效。若指令缓冲区容量设定为两个,且所有请求均能在Icache中成功匹配,同时所有线程束的指令缓冲区均已达到饱和状态,那么在第1个周期,子核心将启动线程束W1的指令发射,并从W0中提取指令。紧接着,在第2个周期,W1将依次发射第二条指令,并从指令缓冲区中获取第三条指令。在第三个阶段,W1的指令缓存区域将保持空缺,这是因为指令3尚处于解码处理阶段。
因此,其贪婪举动注定会落空,它将被迫转而使用来自不同线程束的指令发射。正如我们的实验所展示的,当指令缓冲区中存在三条指令时,这种情形并不会出现。值得关注的是,许多文献中的早期设计普遍假定取指与解码的宽度为两条指令,并且每个线程束的指令缓冲区仅包含两个条目。而且,这些设计仅在指令缓冲区为空时才会进行取指操作。因此,采取贪心策略的线程束在连续执行两条指令后通常会发生变化,这一现象与我们在实验中观察到的结果并不一致。
寄存器文件
我们进行了众多实验,通过执行多种组合的SASS汇编指令,旨在探究寄存器文件的组织架构。在这些实验中,我们特别编写了针对寄存器文件端口施加不同压力的代码,这些代码涵盖了在有无寄存器文件缓存条件下的操作。
现代英伟达 GPU 拥有多种寄存器文件:
与之前的研究有所区别,当前的英伟达GPU在处理寄存器文件端口的冲突时,并没有采用操作数收集器这一方法。在指令的发射与写回阶段之间,操作数收集单元会引入一定的变化性,这一特性导致英伟达的指令集架构(ISA)无法支持固定延迟的指令。正如第4节所述,为了准确处理指令间的依赖关系,固定延迟指令的延迟值必须在编译阶段就确定下来。通过验证特定生产者-消费者指令序列在调整存储体操作数数量时的准确性,我们确认了操作数收集器的缺失。我们注意到,不论寄存器文件端口冲突的次数如何,指令中为规避数据风险而设置的暂停计数段的数值以及执行指令所需的时间均保持恒定。
实验结果显示,每个寄存器文件的存储单元均配备了一个1024位的独立写入通道。同时,若在同一周期内同时执行加载指令和固定延迟指令,则延迟执行的是加载指令。然而,若两个固定延迟指令之间发生冲突,比如一条IADD3指令之后紧跟着一条同样指向同一目标存储体的IMAD指令,这两种指令均不会产生延迟。这表明采用了与Fermi架构中引入的成果队列相仿的方法来应对固定延迟的指令。在此过程中,指令的接收者不会遭受延迟,也就是说,在数据被写入寄存器文件之前,通过旁路技术,结果信息已被提前传递给了接收者。
在读取方面,我们发现各个存储体的传输速率均为1024位。这些数据是通过多种测试手段收集而来,测试内容涵盖了连续执行FADD、FMUL以及FFMA指令所需的时间。以FMUL指令为例,若两个源操作数位于同一存储体,该指令执行后会出现一个周期的空闲;相反,若两个操作数分布在不同的存储体,则不会出现空闲。当三个源操作数均位于同一存储体时,执行FFMA指令将导致系统出现两个周期的闲置时间。
遗憾的是,我们并未成功寻找到一种通用于各类研究场景的读取策略。这是因为,我们注意到空闲周期的出现与指令的种类以及指令中各个操作数的职责紧密相关。经过研究,我们发现,与绝大多数测试实验最为契合的近似方案是,在固定延迟指令的指令发射与操作数读取之间,增设两个中间环节,即控制阶段与分配阶段。其中,控制阶段的内容在前文已有阐述。后者承担着保留寄存器文件读取端口的职责。每个寄存器存储单元都配备了一个1024位的读取端口,而通过运用寄存器文件缓存机制,可以有效缓解读取过程中的冲突问题(具体内容将在后续章节中进行详细阐述)。
实验结果显示,无论指令处于闲置阶段(如仅涉及两个操作数的情况),所有固定延迟指令在读取源操作数时均需三个周期完成。这主要是因为FADD和FMUL指令尽管操作数数量少一个,但其延迟与FFMA指令相同。此外,FFMA指令的延迟不受三个操作数是否位于同一存储体中的影响,始终保持一致。在指令分配环节,若该指令察觉自己无法在接下来的三个周期内完成对所有操作数的读取,它将暂停在当前阶段,导致流水线上游部分停滞,并在此期间产生若干空闲周期,直至它具备在接下来的三个周期内保留读取源操作数所需的所有端口。
(1)寄存器文件缓存
在GPU架构中,引入寄存器文件缓存(RFC)技术旨在减轻对寄存器文件端口的访问压力,同时有效降低能耗。
实验结果显示,英伟达的设计与 Gebhart 等人的研究成果相似。该设计的特点是,RFC 的控制权在编译器手中,且仅应用于常规寄存器文件中带有操作数的指令。至于最终的结果文件结构,我们提及的结果队列表现出了类似的行为。不过,与那篇论文所述不同,这里并未采用两级指令发射调度器,正如前文所述。
针对 RFC 的相关组织,我们的实验发现,在每一个子核心的寄存器文件存储体中,都存在两个与之对应的条目。这些条目各自储存了三个1024位的数值,而这些数值分别对应指令可能使用的三个常规寄存器源操作数之一。综合来看,RFC 的整体容量涵盖了六个1024位数值(即子条目)。需要注意的是,对于某些指令,其操作数可能需要占用两个相邻的寄存器资源,比如在执行张量核心指令时。在这种情形下,这两个寄存器分别来源于不同的存储介质,并且各自被存储在相应的缓存条目里。
编译器对资源分配进行管理。在指令被发出并获取其操作数的过程中,若编译器对某一操作数设定了可复用标志,那么该操作数将被保留在资源复用缓存(RFC)中。若后续指令源自同一线程束,且其寄存器标识符与记录文件中保存的标识符相匹配,同时指令中的操作数位置与触发缓存的指令位置一致,则该指令将直接从记录文件中提取寄存器的源操作数。不论记录文件中是否成功匹配,一旦针对同一存储单元和操作数位置的读取请求到来,缓存中的数据便将失效。清单2中的示例2对此进行了阐释;为了在缓存中定位到R2,第三条指令前的第二条指令需将R2的重用位进行设置,即便R2已经被第二条指令所占用。清单2还通过其他三个示例进一步阐述了RFC的运作机制。

内存流水线
在NVIDIA的现代GPU中,内存流水线的起始环节由各个子核心分别负责处理;而执行内存访问的最终步骤,则由四个子核心共同完成。这一设计的原因在于,数据缓存和共享内存是所有子核心共同使用的资源。在本节内容中,我们将揭晓各个子核心所配备的加载/存储队列的容量,子核心向共享内存结构提出请求的速度,以及不同内存指令类型在执行过程中所表现出的延迟特性。
需指出的是,GPU内存的访问主要涉及两大类别:一类是针对共享内存的访问(即SM本地内存,它被线程块中的所有线程共同使用),另一类则是针对全局内存的访问(即GPU的主存)。
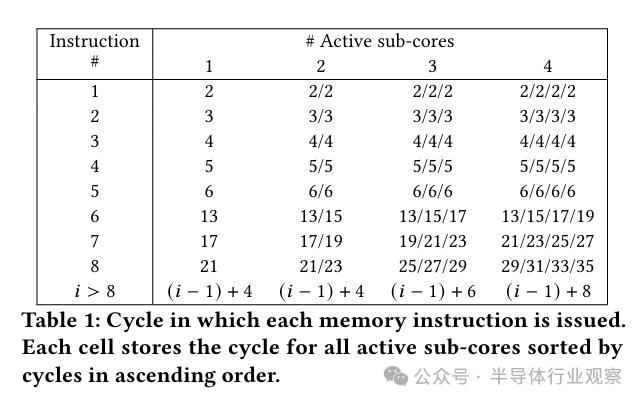
为了研究队列规模与内存带宽之间的关系,我们精心策划了一系列实验:在这些实验中,每个子核心要么负责执行一个warp的指令,要么保持闲置状态。在这些warp中,它们会依次执行一系列单独的加载或存储操作,这些操作能够成功访问数据缓存或共享内存,并且会利用常规寄存器来完成。表1呈现了实验所得数据,其中首列列出了代码指令的序号,而接下来的四列分别呈现了在四种不同子核心激活数量情况下,各个子核心执行相应指令所需的时钟周期。
观察Ampere架构的表现后,我们发现:每个子核心可以连续五个周期内每周期发出一条内存指令,然而,从第六条内存指令起,便会遭遇延迟,而这种延迟的周期数与活跃的子核心数量成正比。据此,我们可以得出以下结论:首先,每个子核心最多能够连续处理五条指令而不会出现停滞;其次,全局共享结构每两个周期便能够接纳来自任一子核心的一个内存请求。在存在多个子核心同时被激活的情境中,各个子核心的第6条指令及其之后的所有指令,需经过两个周期的延迟才会被依次发出。
我们注意到:每个子核心在地址计算方面的处理能力是每4个周期执行完毕一条指令。这一发现是基于在单激活子核心条件下的测试结果——当只有一个子核心处于活跃状态时,发射第6条指令之后将经历4个周期的空档。而当有两个子核心同时激活时,得益于它们共有的结构,每两个周期能够处理一条指令,因此每个子核心都能维持每4个周期发射一条内存指令的效率。随着子核心数量的增加,共享结构的作用逐渐受限。以四个子核心协同作业为例,鉴于共享结构每两个周期最多只能处理一条指令,每个子核心便只能每隔8个周期才能发出一条指令。
在探讨子核心内存队列的规模时,我们推算其存储能力约为4条指令,即便每个子核心具备缓冲5条指令的能力。当指令步入处理单元时,它们会占据队列中的位置,而在完成处理后,则会释放这些位置。
在缓存访问成功并且采用单线程处理的情况下,我们对不同内存指令进行了两种延迟特性的评估:首先,我们关注的是从加载指令发出到其后续消费者指令(或者覆盖相同目标寄存器的指令)能够再次发射的最短时间差,这一特性被称为RAW/WAW延迟(需注意,存储指令并不会引起RAW/WAW类型的寄存器依赖)。第二种情况指的是,从加载/存储指令发出,到它能够再次发射并写入源寄存器的最小时间间隔,这一时间间隔被称作WAR延迟。具体的测量数据详见表2。
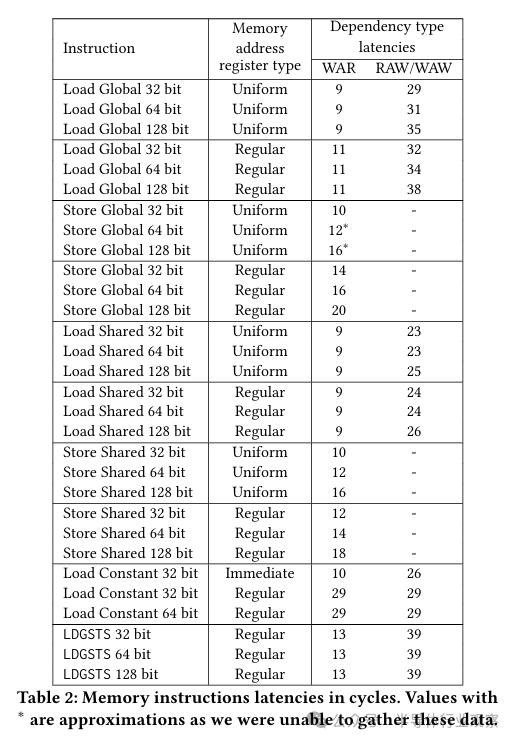
研究结果显示,采用统一寄存器进行地址计算的全局内存访问速度明显快于使用常规寄存器。这种性能差异主要来自于地址计算效率的提高,因为统一寄存器被warp内的所有线程共同使用,从而只需计算一个内存地址;相比之下,常规寄存器则可能要求每个线程分别计算不同的内存地址。
此外,共享内存的加载延迟普遍较全局内存低,并且其WAR延迟在常规和统一寄存器使用场景中保持稳定,而在统一寄存器场景下,RAW/WAW延迟可减少一个周期。这种WAR延迟的稳定性揭示了共享内存的地址计算是在共享结构而非子核心本地结构中进行的,因此,一旦完成源寄存器的读取,WAR依赖即可解除。
延迟特性还与读写数据的量级有关:在WAR依赖方面,加载指令的延迟并不会因为数据量的大小而改变,这是因为它的源操作数仅用于地址的计算;然而,存储指令的WAR延迟会随着写入内存的数据量增大而增加,这是因为这些数据作为源操作数需要从寄存器文件中提取。针对RAW/WAW的依赖性(仅限于加载指令部分),随着读取的数据量变大,延迟时间也会相应增长,这是因为需要将更多的数据从内存传输到寄存器文件中。根据实际测量结果,这种数据传输的带宽达到了每周期512比特。
我们注意到,常量缓存的写入后读延迟明显大于全局内存的加载动作,但读后写和写后写延迟则相对较小。目前,我们尚未明确这一现象的确切原因。然而,实验结果表明:访问常量内存的固定延迟指令与LDC(加载常量)指令在缓存使用上处于不同的层次。在执行LDC指令将特定地址预加载至常量缓存并确保其操作完成之后,我们向同一地址发送了固定延迟指令,实际测量结果显示出现了79个周期的延迟,这一结果与预期的零延迟存在差异。这一现象表明,当固定延迟指令访问常量地址空间时,它们是利用L0 FL(固定延迟)常量缓存,而LDC指令则是在使用L0 VL(可变延迟)常量缓存。
在最终的分析中,我们聚焦于LDGSTS指令,这是一项特别为减轻寄存器文件负担以及提高数据传输速度而开发的指令[38]。它允许直接将全局内存中的数据存入共享内存,而无需借助寄存器文件,进而有效节省了指令和寄存器的使用资源。测试结果显示,该延迟与数据粒度并无关联:在地址计算完成之后,WAR类型的依赖关系便保持恒定,不再受影响;至于RAW/WAW类型的依赖,它们在读取阶段结束后也会解除,这一过程同样不受数据粒度的影响。
建模实现
我们从零起步,精心打造了Accel-sim框架模拟器的流多处理器(SM)/核心模型。我们通过调整流水线,实现了文中阐述的内容以及图3所呈现的各个细节。接下来,我将简要介绍这些新增的主要组件。
我们为每个子核心增设了配备流缓冲区预取功能的L0指令缓存。该L0指令缓存与常量缓存相连接,二者之间通过参数化的延迟与L1指令缓存或常量缓存实现互通。
依据先前的测试数据或贾等人阐述的安培架构,我们确定了缓存规模、层级设计以及响应时间。在指令发射环节,我们进行了调整,旨在实现:对控制位进行管理、对新加入的具有固定延迟特性的指令在L0常量缓存中执行标签定位,以及开发了一套由编译器引导的指令发射调度策略,该策略优先考虑贪心原则和最年轻优先级(CGGTY)。我们引入了控制环节(其中指令会提升依赖计数器的数值)以及分配环节(在此环节中,固定的延迟指令会检测在访问寄存器文件及其缓存时是否发生了冲突)。
针对内存指令,我们为各个子核心设计了一个独立的模块,同时,我们还为子核心间搭建了一个共享模块,其延迟特性在上一节已有详细说明。
另外,鉴于阿卜杜勒哈利克等研究者已证实张量核心指令的响应时间与操作数的数值类型及规模相关,我们据此对模型进行了调整,确保对不同类型和规模的操作数应用恰当的延迟处理。
我们的模型构建还涵盖了以下要点:在缺乏专用双精度执行单元的子核心架构中,我们为所有子核心共同配置了双精度指令执行流水线。同时,我们对涉及多个寄存器的操作数的读写时序进行了精确建模,与之前仅用一个寄存器进行近似处理的做法相比,有了显著改进。另外,我们还对先前研究中提到的指令地址问题进行了修正,消除了不准确之处。
除了在模拟器中成功实现了新的SM或核心模型,我们还对跟踪工具进行了功能扩展。现在,该工具能够记录并存储所有操作数(包括常规寄存器、统一寄存器、谓词寄存器以及立即数等)的唯一标识符。此外,我们还实现了对指令控制位的获取功能,这是因为NVBit本身并不支持对这类控制位的访问。这一过程是通过在编译阶段运用CUDA的二进制实用工具,将SASS(即英伟达汇编语言)代码提取出来而完成的。因此,它要求对应用程序的编译流程进行相应的调整,确保在编译过程中生成与特定微架构相关的代码,而非采用即时编译技术。遗憾的是,针对部分属于 Deepbench 的内核,英伟达的工具并未提供 SASS 代码,这导致我们无法获取这些指令的控制位。因此,在模拟这些应用程序时,我们采取了混合策略:对于缺乏 SASS 代码的内核,我们采用常规的计分板技术;而在其他情况下,则利用控制位。
我们对这款工具进行了升级,使其具备了通过描述符来捕捉对常规缓存以及全局内存的访问能力。尽管有人宣称后者类型的内存访问是在Hopper架构中被引入的,然而我们观察到Ampere架构实际上已经开始采用了这些技术。描述符是一种新型的内存引用编码手段,它通过两个操作数来实现。第一个操作数属于一种通用的寄存器,它的作用是对内存指令的语义进行编码处理,而第二个操作数则负责对地址信息进行编码。我们已对跟踪器进行了功能扩展,以便能够捕捉到地址信息。然而,遗憾的是,目前尚未追踪到统一寄存器中编码的具体行为。
我们打算对外公布针对Accel-sim框架所进行的全部模拟器和跟踪器的调整内容。
验证
在本节内容里,我们将对所提出的GPU核心微架构的精确度进行检验。首先,在第7.1小节中,我们将详细介绍所采用的研究方法。随后,在第7.2小节中,我们将对设计方案进行有效性验证。紧接着,在第7.4小节中,我们将探讨寄存器文件缓存及寄存器文件读端口数量对准确度与性能所产生的影响。稍后,在第7.3节中,我们将深入探讨设计中的两个不同组件(例如指令预取器)对设计的影响;接着,在第7.5节中,我们将对依赖检查机制进行详细分析。最终,在第7.6节中,我们将讨论该模型如何能够无障碍地与安培架构以外的其他英伟达架构相兼容。
方法
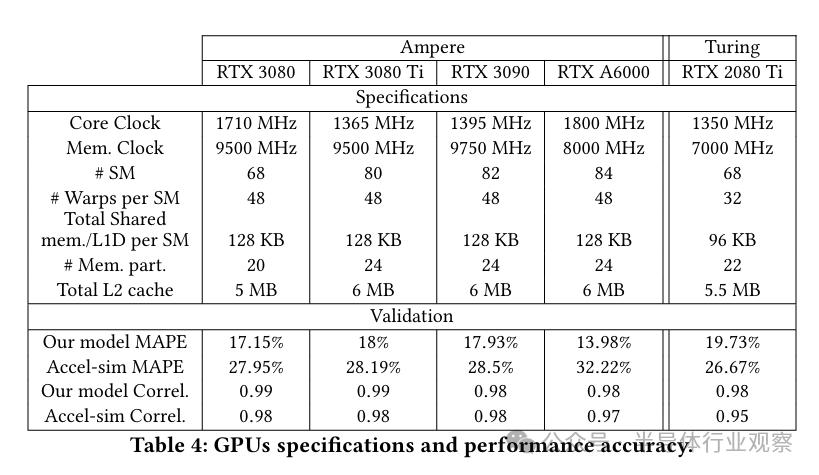
我们通过将模拟器输出的数据与在实体GPU上收集的硬件计数器数据相对照,以检验所设计的GPU核心的精确度。为此,我们选取了四种不同型号的安培架构GPU,具体型号及规格详见表4。这些GPU均配备了CUDA 11.4和NVBit 1.5.5软件。我们将对自家的模型或模拟器进行评估,并与之原始的Accel-sim模拟器框架进行对照,鉴于我们的模型是在其基础上构建而成的。

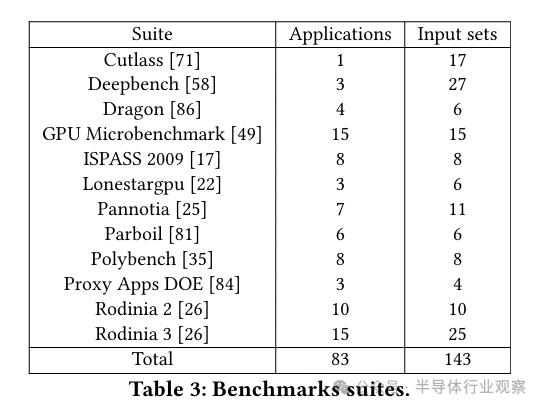
我们采用了源自12个不同套件的多种基准测试工具。具体所用的套件清单、应用程序数量以及不同输入数据集的数目,详见表3。总体来看,我们一共运用了143项基准测试,其中83项是独立的应用程序,而其余的则仅是调整了输入参数。
性能准确性
表 4 展示了针对每个 GPU 真实硬件,两种模型(即我们所提出的模型与 Accel-sim 模型)所计算出的平均绝对百分比误差(MAPE)的具体数值。观察所有评估的GPU,我们发现,我们的模型在准确性上远超Accel-sim模型。特别是针对性能最强的GPU——英伟达RTX A6000,我们模型的平均绝对百分比误差(MAPE)仅为Accel-sim模型的一半以下。在相关性方面,两者表现相近,不过我们的模型略占优势。
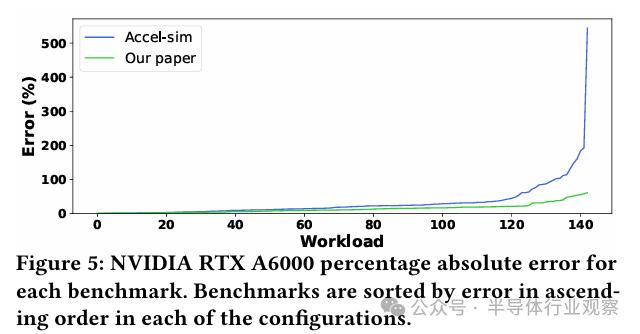
图 5 展示了英伟达 RTX A6000 以及 143 个基准测试的结果,这些测试在两种不同模型下产生的绝对百分比误差(APE)被按照误差大小进行了排序。观察结果显示,在所有测试的应用程序中,我们的模型展现出的绝对百分比误差普遍低于 Accel-sim 模型,而且在其中一半的应用程序中,这种差异尤为明显。除此之外,我们发现Accel-sim模型在十个应用场景中的绝对误差百分比均超过或等于100%,最极端的误差百分比甚至高达543%,相比之下,我们的模型在所有测试中的绝对误差百分比均未超过62%。以第90个百分位数为衡量尾部精确度的标准,Accel-sim模型的绝对百分比误差高达82.64%,相较之下,我们的模型误差仅为31.47%。这一对比充分显示出,我们的模型在准确性及可靠性方面均优于Accel-sim模型。
指令预取的敏感性分析
流缓冲区指令预取器的特性对全局模型的精确度产生了显著的作用。在本部分内容中,我们详尽探讨了多种配置条件下的误差表现,这些配置包括但不限于关闭预取器、采用理想的指令缓存机制,以及运用了不同条目数量的流缓冲区预取器,具体条目数量分别为1、2、4、8、16和32。所有实验配置均以英伟达RTX A6000为硬件平台。具体每个配置的MAPE误差值可参照表5。可以看出,大小为 16 的流缓冲区能获得最佳的准确性。
在表 5 所展示的加速比数据中,我们进一步发现,GPU 中诸如流缓冲区之类的简易预取器,其性能几乎可与理想的指令缓存相媲美。这主要得益于每个子核心内的不同线程束往往执行相同的代码区域,加之通用计算 GPU(GPGPU)应用程序的代码控制流程相对简单,因此,预取接下来的 N 行代码通常能够取得良好的效果。需留意的是,鉴于GPU无法进行分支预测,故而采用Fetch Directed Instruction预取器并无实际意义,因为这样做势必要增加一个分支预测器的配置。

在探讨模拟的精确度时,我们发现,即便不深入探究指令缓存优化的效果,仅仅采用理想的指令缓存机制,即可在确保较高模拟准确度的前提下,显著提升模拟的运行效率。然而,在控制流至关重要的基准测试中,例如dwt2d、lud或nw,若采用完美指令缓存或未使用流缓冲区,将会引起显著的不精确度(与采用完美指令缓存相比,误差超过20%;与未启用预取指令缓存相比,误差更是超过200%)。这种误差的产生是由于完美指令缓存未能有效捕捉到在多个代码片段间频繁切换所导致的性能损耗,同时,若不采用预取机制,则会过分影响程序其他模块的运行效率,这也反映出当前的基准测试尚有优化提升的余地。
寄存器文件架构的敏感性分析
表6揭示了寄存器文件缓存的实际情况,并详细说明了增加每个存储体的寄存器文件读端口数量对模拟精确度和系统性能的具体影响。此外,它还呈现了在理想操作条件下(即所有操作数均能在单个周期内获得)的测试结果。在各种基准测试中,所有配置的平均性能与准确性保持一致。然而,若对某些特定的基准测试进行更深入的分析,例如针对计算密集型的MaxFlops(Accel-sim GPU Microbenchmark)以及设置为sgemm参数的Cutlass,我们便能观察到更为细致的差别。这两个基准测试高度依赖于固定延迟的算术运算指令,此类指令对于寄存器文件访问所引发的延迟尤为敏感,尤其是考虑到它们通常需要三个操作数来完成每条指令的执行。
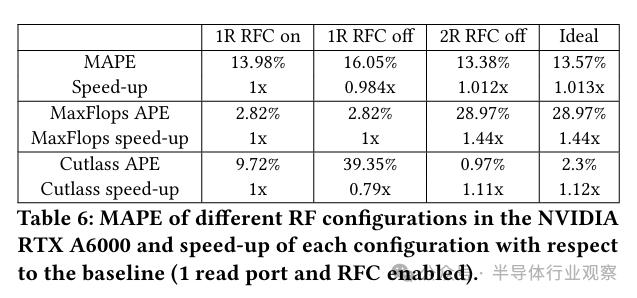
MaxFlops的性能不受RFC是否存在的影响,始终一致,这是因为仅有一条静态指令会调用它。特别值得一提的是,当每个寄存器文件存储体启用两个读端口后,性能有了大约44%的提升。鉴于每条指令通常需要三个操作数,而四个读端口(每个存储体配备两个)已足够应对需求,这种优化是相当合理的。相较于其他方面,在模拟精确度的评价标准下,这两个读取端口的设置显现出了明显的差异。
在采用 sgemm 配置的 Cutlass 中,由于缺少寄存器文件缓存,单端口配置的性能显著降低,降幅达到0.78倍。这种性能的降低与观察到的程序中35.9%的静态指令至少在一个操作数中利用寄存器文件缓存的现象相吻合。引入每个存储器所配备的双端口寄存器文件之后,系统性能提升了12个百分点,这一数据反映出寄存器文件与缓存结构尚存在优化余地。
总的来说,寄存器文件架构及其缓存对于特定基准测试的结果具有显著影响,因此对其进行精确的模拟显得尤为关键。每个存储单元配备一个端口和一组缓存,其平均性能与拥有无限端口数量的寄存器文件相当,然而在某些特定的基准测试中,两者之间的差距依然显著,这暗示了该领域可能蕴藏着丰富的研究价值。
依赖管理机制分析
在本部分内容里,我们对本文阐述的软硬件依赖处理机制对性能与占用面积的影响进行了探讨,并且将其与先前几代GPU所采用的常规计分板技术进行了对比。表7中呈现了这两个关键指标的具体数据。其中,面积消耗是以一个SM(Streaming Multiprocessor)的标准寄存器文件面积(256KB)为基准进行报告的。
基于传统计分板的运作原理,其所需条目数量必须与可写入寄存器的数量相匹配,这包括每个线程束的332个条目,其中255个用于常规寄存器,63个用于统一寄存器,7个用于谓词寄存器,以及另外7个用于统一谓词寄存器。除此之外,还需设置两个计分板,一个用于识别写后写(WAW)或写后读(RAW)冲突,另一个则用于检测读后写(WAR)冲突。即便指令是按照既定顺序发布的,但由于存在可变延迟的指令,操作数的读写顺序可能会被打乱。以内存指令这类可变延迟指令为例,一旦发出,它们会被放入队列中,并有可能在较新的算术指令完成写入操作并记录结果之后,去读取其源操作数。若这两者的源操作数和目的操作数恰好一致,便会产生读后写的冲突问题。尽管第一个计分板上的每一条目仅需一位即可,但伴随每一条目消费者数量的攀升,第二个计分板便需配备更多的硬件设施。若每一条目能够容纳高达63名消费者,那么一个单独的线程束在处理依赖关系时,将至少需要2324位(即332加上332乘以2的63加1次方对数)的容量。在整个SM中,这相当于111,552个单位,其占比达到了寄存器文件总量的5.32%。
本文所提出的软硬件架构涉及六个六位数的依赖计数器、一个四位数的暂停计数器以及一个yield位。这样的配置意味着每个线程束仅需41位,而每个SM则需1968位。在成本方面,这一配置仅占寄存器文件总量的0.09%,显著低于计分板方法。
总的来说,采用控制位的软硬件协同设计在性能上胜过其他替代选项,并且其所需的面积几乎可以忽略。尤其是在英伟达Hopper这样的GPU中,它支持每个SM最多拥有64个线程束,与计分板相比,这种差异更为突出。具体来看,控制位方案的开销仅为0.13%,而63个消费者参与的计分板机制,其开销则高达7.09%。此外,我们注意到,采用由两个计分板构成的计分板机制——一个针对 RAW/WAW 冲突,另一个针对最多可支持 63 个消费者的 WAR 冲突——在模拟精确度方面,其表现与使用控制位相仿。鉴于此,对于那些未公开控制位数值的应用程序(例如 Deepbench 基准测试套件中的某些内核),这种机制可作为一个可行的替代选择。
对其他英伟达架构的适用性
本文重点探讨了英伟达的安培架构。同时,我们研究得出的结论同样适用于其他架构,例如图灵架构。在表4中,我们不仅呈现了四个安培架构GPU的测试结果,还展示了一个图灵架构GPU的数据。具体到英伟达RTX 2080 Ti,我们的模型在MAPE指标上相较于Accel-sim有了6.94%的提升。
尽管我们已在图灵与安培架构上对该模型进行了验证,但我们的研究结论亦适用于其他英伟达架构。根据英伟达的公开声明及SM架构图,显著的架构变革主要涉及张量核心的改进、光线追踪单元的强化,以及同一TPC内SM间的分布式共享内存等细微功能。尽管如此,为了确保模型能够适应这些不同的架构,我们仍需对某些指令(例如内存指令)的响应时间进行评估。
相关工作
在学术领域与工业界,模拟器作为衡量计算机架构设计理念的关键手段,其重要性不言而喻,原因在于它能够以较低的成本对新设计进行评估。不仅如此,模拟器还能有效验证设计方案与实际硬件的契合度。即便是通用计算GPU,这一领域也不例外,诸如英伟达等业界领先企业,已经对外公布了其内部模拟器(如英伟达架构模拟器,NVArchSim或NVAS)的开发流程。在学术研究界,存在两款广受欢迎的开源模拟器。其中之一名为MGPUSim,该模拟器专门用于模拟AMD的GCN 3架构,并且特别适用于那些能够支持虚拟内存功能的多GPU系统。另一个可供选择的模拟器是Accel-Sim框架,该框架具备周期精确的特点,并且是业界领先的跟踪驱动模拟技术。它能够兼容CUDA应用程序,并模拟出与英伟达现代架构相似的系统。此外,Accel-Sim框架是在早期的GPGPU-Sim 3模拟器基础上发展而来的。
在众多文献资料中,众多研究项目专注于对CPU架构组成部分进行逆向分析,比如对英特尔处理器中的分支预测机制或缓存系统进行深入研究。
针对英伟达的GPU,众多研究项目已着手探究其特定部件的细节。Ahn及其团队对英伟达Volta和安培架构的片上网络进行了逆向分析。Lashgar等人则专注于研究英伟达Fermi和Kepler架构在处理内存请求方面的性能。Jia 等研究者对 Volta 和 Turing 架构的缓存特性进行了阐述,包括缓存行的大小、关联性、指令的延迟,以及寄存器文件的若干细节。Khairy 等研究者则深入探讨了 Volta 架构中的 L1 数据缓存和 L2 缓存的设计方案。Abdelkhalik 等研究者构建了安培架构中 PTX 与 SASS 指令间的关联及其执行时的延迟情况。在张量核心方面,众多研究文献如[31, 43, 44, 53, 54, 72, 82, 91]等,对它的可编程特性以及微架构进行了探讨。张等人对Turing与Ampere架构的TLB实施了逆向工程研究,其目标在于对多实例GPU实施攻击。在探讨现代英伟达GPU架构的控制流方面,Shoushtary等人针对Turing架构的控制流指令给出了一种恰当的语义解释,与实际硬件的追踪结果相比,误差仅有1.03%。Amert 等人深入探讨了英伟达 Jetson TX2 系统中的 GPU 任务调度机制,并分析了其与 ARM CPU 之间的交互过程。而 Wong 等人则详细阐述了早期 Tesla 架构中的众多关键组件,包括缓存、TLB、SIMT 控制流行为以及协作线程阵列(CTA)屏障等。
在先前对其他GPU制造商的研究中,Gutierrez及其团队强调,在模拟阶段,直接运用AMD GPU的机器指令集架构(ISA)而非借助中间语言,对于精确识别性能瓶颈和探索可能的解决方案显得尤为关键。此外,GAP 工具具备区分实际 AMD 显卡与在 gem5 模拟环境中显卡差异的能力,这一功能显著增强了 gem5 对 AMD 显卡的模拟精确度。最终,Gera 等研究者提出了一种新的模拟架构,并对英特尔集成显卡的特性进行了详细阐述。
自英伟达的Kepler架构开始,编译器提示(亦称控制位)便在GPU领域得到了应用。Gray等人对这些控制位进行了详细阐述。在Kepler、Maxwell以及Pascal架构中,大约每3至7条指令中,就有一条是由编译器自动添加的提示指令。贾等人提到,例如Volta或Turing等较新的架构已经将指令的位宽从64位提升至128位。由此,这些新架构不再依赖特定的指令来执行提示功能,而是将提示位嵌入到每条指令之中。这些提示位不仅有助于提高硬件的性能,同时还能有效避免数据冲突,从而保障程序的准确性。中央处理器会采纳编译器提供的指示,以协助硬件更有效地分配和使用各类资源。这些指示旨在增强CPU中各个模块的功能,例如数据旁路技术、分支预测以及缓存系统等。
据我们所掌握的信息,我们的研究首次对现代英伟达GPU的核心微观结构进行了披露,并成功构建了该结构的精确模拟模型。在此过程中,我们揭示了一系列新颖的特性,如对控制位含义的全面阐释、涉及这些控制位的微观结构调整、指令发射调度器的运作机制、寄存器文件及其关联缓存的微观结构,以及内存流水线的多个层面。这些方面对于准确建模现代英伟达 GPU 至关重要。
结论
本研究通过在实体硬件上实施逆向操作,深入解读了业界现代英伟达GPU的微观结构。我们深入分析了指令发射环节的运作机理,涉及对线程束准备状态的探讨,同时观察到线程束间的指令发射调度器采纳了由编译器指导的贪婪优先级以及年轻优先级(CGGTY)的调度策略。除此之外,我们还详细阐述了寄存器文件的多项特性,比如端口的数量和宽度等方面。我们详细解读了注册器文件缓存运作的机制。同时,本文揭示了内存流水线的关键特性,包括加载/存储队列的规模、子核心间的竞争状况,以及内存指令的访问粒度如何作用于响应时间。另外,我们对指令获取阶段进行了深入研究,并提出了一项适应当前英伟达GPU需求的指令获取策略。
此外,本文对先前公布的关于控制位的信息进行了梳理、详尽阐述和拓展,并对其进行了归纳总结。
在模拟器中,我们对所有细节进行了细致的建模,同时,将新构建的模型与实际硬件进行了对照。比较结果显示,该模型在周期精确度上相较先前模型提升了18.24%以上,且与实际状况更为吻合。
我们进一步证实了,在GPU环境中,采用基于基础流缓冲区的指令预取技术,在模拟的精确度和性能上均有上佳表现,其效果几乎等同于理想的指令缓存。同时,我们也揭示了在现代英伟达GPU中,依托控制位的依赖管理策略相较于其他方法,如常规的计分板策略,具有显著优势。
最终,我们对寄存器文件缓存以及寄存器文件读端口的数量进行了分析,探究了它们对模拟精度和系统性能所产生的作用。
总体来看,我们能够得出这样的结论:GPU的设计是硬件与编译器共同协作的成果,编译器负责指导硬件如何处理那些依赖关系,同时它还会提供一些提示信息,这些信息有助于提升性能并增强能效。





