


原本心存幻想,以为经过医学考试的考验,大模型距离成为“AI医生”仅有一步之遥。然而,牛津大学最新进行的这项研究,却如同一记重锤,给了我们当头一棒。
论文地址:
你在新闻报道中频繁看到的诸如“AI诊断精确度竟达99%!”以及“大型模型力压专业医师!”等引人注目的标题,它们所宣称的准确性真的可信吗?
牛津的研究小组精心挑选了1298名英国民众,并为他们创设了十个贴近生活的医疗情境。
他们需仿照现实生活中的做法进行判断:目前我所呈现的症状是否严重?是应该独自承受、前往社区医院,还是必须立即赶往急诊室?部分人拥有大型模型提供辅助,而另一些人则需依赖Google自行查询。
此次参与对决的,并非微不足道的简单模型,而是GPT-4o、Llama 3以及Cohere的Command R+。这些模型在理论上均达到了顶尖AI的级别。
然而,结果如何呢?当模型独立进行答题时,其表现堪称完美:GPT-4o能够准确识别94.7%的疾病,其推荐的诊疗方案也有64.7%是正确的,Llama 3和Command R+的表现同样不俗。你以为一旦AI上线,所有人都能得到救助吗?
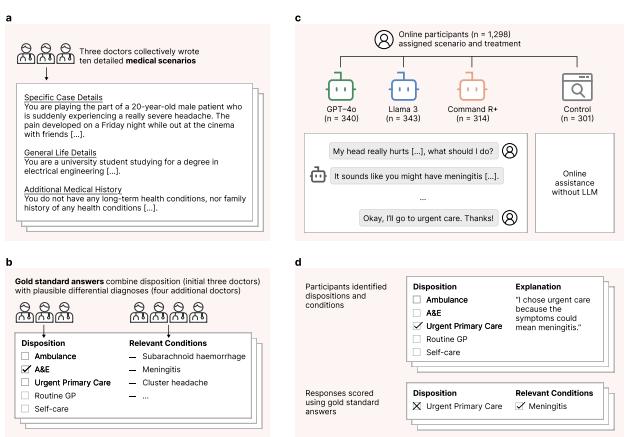
研究方案包括:(a) 三位医生共同撰写了十个医疗案例,经过多次修订,他们对于处理方式(从自我护理至呼叫救护车,共分为五个等级)达成了共识;(b) 另有四位医生负责提供鉴别诊断,并将这些信息汇总,形成了标准答案;(c) 我们招募了1298名参与者,将他们随机分为四组,每组接受一个案例的测试。实验组在判断过程中可借助大型语言模型,而对照组则可采取任何方法进行判断,其中大多数人会选择使用搜索引擎或凭借个人知识。测试对象需选定处理方案并阐述具体病症情况。每位测试者需分析两个案例,总计每组需汇总600份数据,最终以既定标准答案对测试结果进行评定。
一旦真实用户开始与大型模型进行互动,情况便发生了转变:借助AI辅助后,人们仅在34.5%的情况下能够准确说出疾病名称,这甚至比未借助AI、自行查阅资料的情况还要糟糕。选择正确处理方法的可能性,并未比未使用AI的对照组有所提升。AI的智能程度越高,用户似乎反而越容易感到困惑。
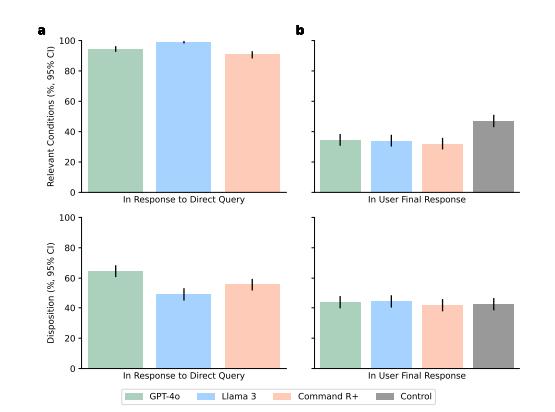
大语言模型单独使用及与用户协作的表现

为何会出现这种情况?研究团队指出,问题并非出在AI本身,而是“人与AI”的协作过程中出现了脱节。举例来说,当用户在描述症状时信息不完整,AI便可能误诊;AI提供2.2个可能选项,而用户却仅接受1.33个,其中三分之一的选择甚至错误。即便模型解释得再清楚,用户未能理解,或者未按建议行事,那些医学知识就如同被封闭在了一个无解的谜团之中。
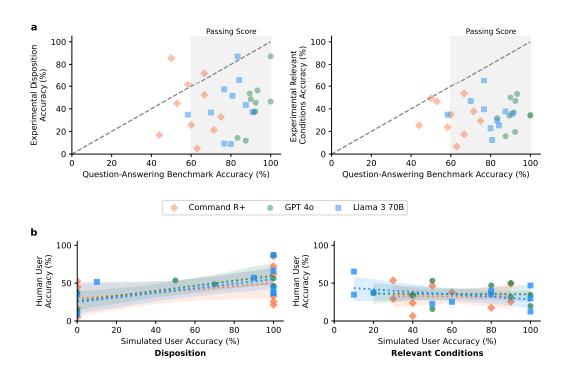
如上图所示,对多个大型语言模型(例如GPT-4o、LLaMA 3 70B以及Command R+)在医学问答任务(MedQA)中的表现进行了观察,并且这些模型的表现与人类用户的回答进行了比较。研究结果显示,尽管该模型在常规的问答测试中普遍能够达到甚至超越人类的标准表现(即60%的准确率),然而在模拟临床情境下的判断任务中,比如确定最合适的治疗方案和相关的疾病状况,其表现却显得不够稳定。另外,模拟用户在判断准确性方面与实际人类用户的表现密切相关,这表明模拟用户在实验中能够很好地反映人类的行为特征。
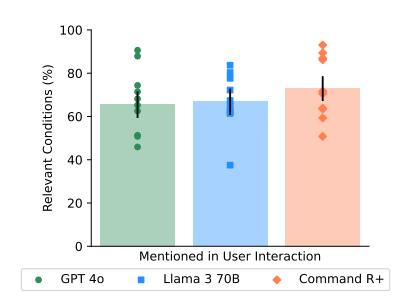
图注:交互过程中的相关病症识别情况
这不就是我们生活中常见的那些“明明有详细说明书却还是装错了家具”“菜谱明明写得明明白白,最后却炒糊了”的尴尬时刻吗?技术再高超,如果使用者不懂得如何运用,那就一切徒劳。你为父母购置了最先进的智能手机,他们却仅仅用它来打电话和发微信;即便是再厉害的AI医生,在面临现实生活中的“零散信息、突发慌乱、沟通误解”等问题时,也会感到无能为力。
众多人士仍沉醉于“AI即将有效缓解医疗资源短缺”的幻想之中。然而,牛津的研究团队却浇了一头冷水:在实验室中取得的优异成绩,一旦进入现实应用,其效果便大打折扣。即便AI在考试题目和模拟病人测试中表现出色,这并不能证明其能够妥善处理真实用户的需求。AI擅长答题,却无法主动追问、不知如何引导患者补充信息——这正是其最大的不足之处。
更有讽刺意味的是,那些用于模型测评的MedQA等考试题目,AI能够轻松取得满分,然而一旦涉及到与真人进行互动,却出现了“翻车”的情况。你让AI与模拟病人对话,其表现甚至不如与真实用户交流。AI与AI之间的交流自然流畅,但在现实世界中,人类的表达、记忆、情绪,甚至是敷衍的态度,却成为了最大的难题。
当然,这项牛津的研究本身具有一定的“半真实”性质;研究对象均为健康个体,他们按照预设的剧情模拟出患病状态,与实际患有疾病、焦虑不安且信息杂乱的真实患者相比,仍存在一定的差距。在研究中,AI系统采用的是API接口,而非GPT那样的连续对话模式。研究过程中缺乏上下文信息,也不具备“链式思考”的能力,更未融入现实中的各种“人性化提示”。
即便如此,该实验依然向我们发出了警示:AI并非不可应用,但“AI与人相结合”的运作模式,才是最为棘手、难以攻克的关键环节。
我们早已习惯了坚信“技术能够一劳永逸地解决问题”,然而却忽视了现实世界的复杂、粗糙以及其不确定性。你以为一旦AI医生投入使用,就能让一线医生从繁重的工作中解脱出来吗?然而在真实的诊疗环境中,信息总是不完整,沟通常常陷入混乱,而决策过程则充满了不确定性。这就像生活中那些因为手抖而拍出的模糊照片,它们才是最贴近真实“医学场景”的写照。
因此,AI在医学领域的未来发展,并非仅仅是模型评分的竞技,更是一场关于“如何使普通人能够顺畅地与AI沟通”的持久修行。AI若要深入医疗领域的最前沿,所面临的挑战和需要跨越的道路,无疑是漫长而又遥远的。
本文来自微信公众号,作者:文摘菌,36氪经授权发布。





