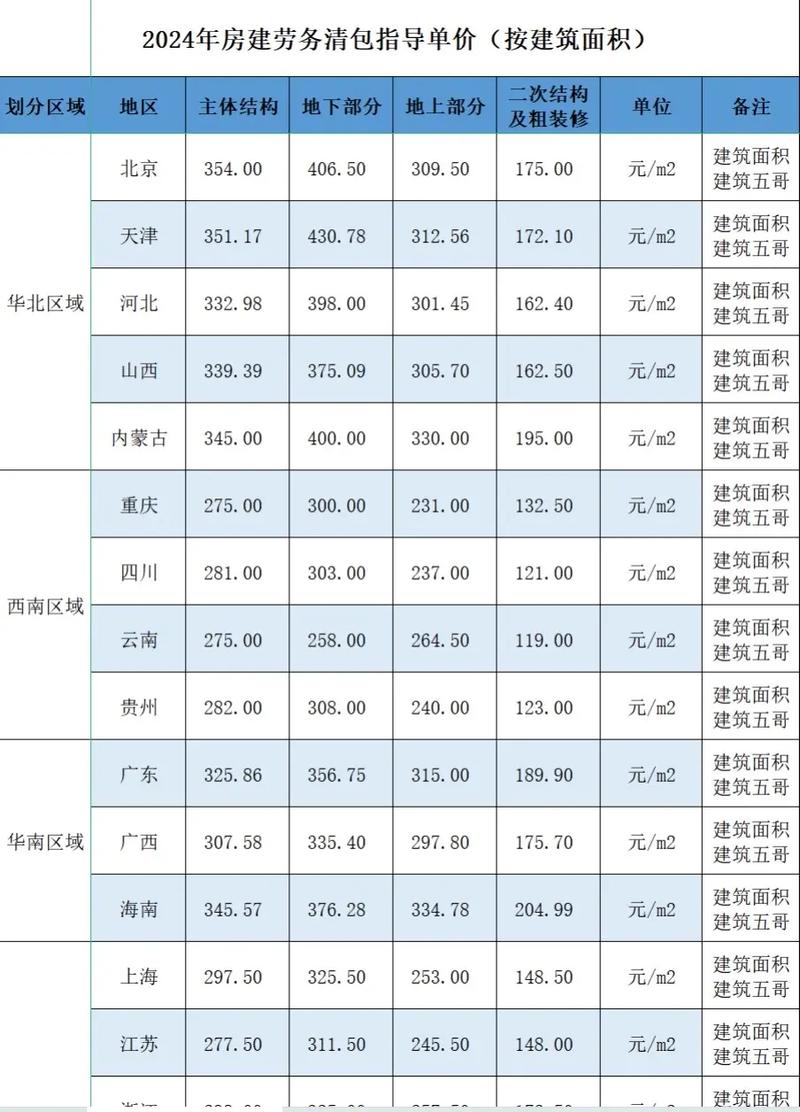
最近,推理语言模型(RLMs)已经成为主流。
最新发布的、性能最强的LLM大都是推理模型。
特别是DeepSeek-R1发布了,这引发了广泛的社会影响,与此同时,也点燃了研究社区对推理的热情。
然而,DeepSeek-R1的某些实现细节尚未完全公开,举例来说,像DeepSeek-R1-Zero以及经过蒸馏的小模型这类细节并未完全开源。
因此,许多针对DeepSeek-R1进行复制的研究出现了(见图1),这些研究尝试通过相似的训练流程,利用完全开源的训练数据,来重现DeepSeek-R1的优异性能。
这些研究对监督微调(SFT)的可行策略进行了探索,还对基于可验证奖励的强化学习(RLVR)的可行策略展开了探索,重点关注数据准备,也重点关注方法设计,最终产出了不少宝贵经验。
为此,本文总结了近期的这些复现研究,以启发未来的探索。

论文地址:
本文的结构大致对应DeepSeek-R1的训练流程,介绍当前在SFT方面的复制工作,介绍当前在RLVR方面的复制工作,介绍当前在其他增强推理能力技术方面的复制工作:
监督微调可提升语言模型推理能力,研究团队全面梳理了相关研究,这些研究是通过监督微调来增强语言模型推理能力的 。
用可验证奖励强化学习来训练推理语言模型,研究团队介绍了近期的相关研究,该研究通过可验证奖励强化学习训练RLMs,还详细阐述了训练数据,以及学习算法和奖励系统设计。
研究团队注意到,尽管DeepSeek-R1推动了RLMs的训练,然而仍有许多监督策略未被探索,他们提出了RLMs的更多发展方向,其中包括奖励建模和偏好优化,并且分析了当前RLMs的优缺点,比如强大的分布外泛化能力以及偶尔的过度思考。
通过监督微调提升RLMs
推理数据集大多从收集问题起步,这些问题来自多样化领域,比如数学、科学、编程和谜题,其数据来源包含现有的基准测试或者网络爬取 。
在收集原始数据后,通常会进行多轮过滤以提升数据质量,包括:

为保证数据的覆盖面与丰富性,许多数据集在选择时明确强调难度和多样性,通常会采用启发式方法,或依据模型通过率,优先挑选较难的问题。
此外,大多数数据集依靠经过验证的思维链,也就是COTs,来确保正确性,依靠它来确保质量。
验证方法因领域而异,例如:
这种方法结合了领域验证与选择性保留,它能让数据管理人员提炼出高质量的推理轨迹,进而更好地支持监督微调。
这些数据集覆盖多个领域,然而,如表1所示,大多数数据集主要集中在数学和编程任务上,涉及更广泛推理任务(像科学、逻辑谜题和开放性问题)的覆盖率依旧相对有限。

值得注意的例外有DeepSeek-R1和AM,它们在数据收集过程中纳入了更广泛的领域,它们在蒸馏过程中也纳入了更广泛的领域,其目的在于培养更通用的推理能力。
长度分布
图2展示了数据集的token长度分布情况。
这些数据集的长思维链(CoTs)均源自同一个教师模型,即DeepSeek-R1,然而它们的分布有着明显差异。
AM的数据集倾向于较短的序列,Synthetic - 1的数据集也倾向于较短的序列,Light - R1的分布范围更广,Open - R1的分布范围也更广,Light - R1的尾部更长,Open - R1的尾部也更长,这表明它们包含更多复杂问题,这些问题通常会引发更长的思维链。
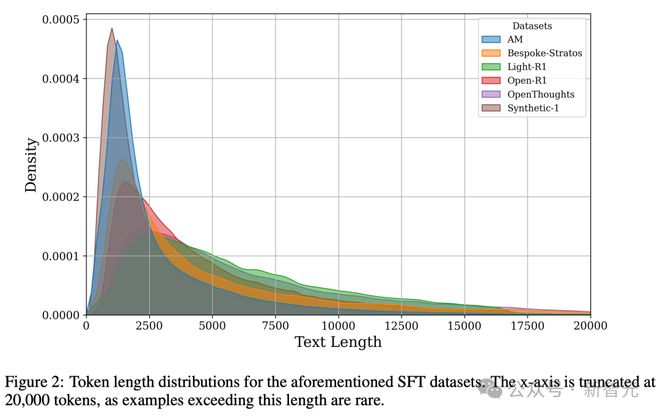
图3展示了常用数学推理数据集之间的交叉引用结构,该图清晰呈现了数据集之间的依赖网络,还呈现了数据集之间的共享数据,这有助于研究人员更好地解读结果,能避免重复的训练或评估设置。
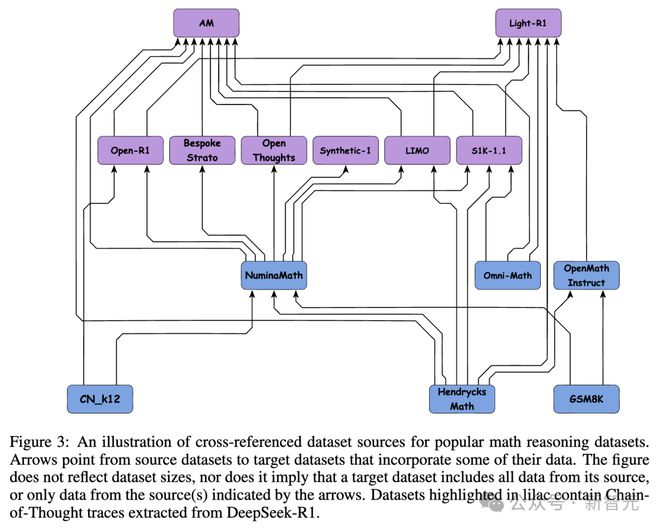
图中的箭头,是从源数据集指向目标数据集的,目标数据集包含源数据集的部分数据。以淡紫色高亮显示的数据集,包含从DeepSeek-R1提取的思维链(Chain-of-Thought)轨迹。
性能比较
在实践里,SFT阶段十分关键,它能让基础模型从更强的模型中学习,从而获得高质量推理轨迹 。
表2展示了常见数学推理基准上SFT结果的比较,这些基准包括AIME24/25和MATH500等,突出了不同数据集选择的影响,也突出了初始模型检查点的影响。
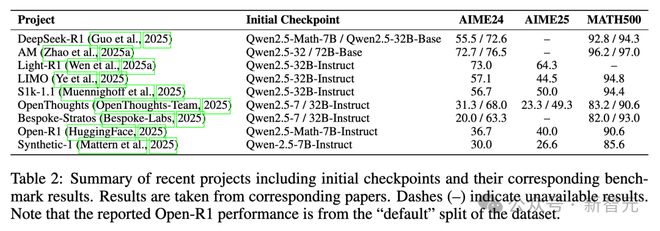
许多方法强调通过增加训练样本数量来提升性能,然而,LIMO和S1k-1.1表明,精心挑选小规模数据集,也能取得优异成果。
训练细节
对于复杂推理等长上下文任务,通常会对模型配置中的RoPE缩放因子(θ)进行调整,还会对最大上下文长度进行调整,以此来支持扩展的上下文能力。
请提供需要改写的句子,以便我进行操作。
此外,通常采用打包(packing)技术来提高训练效率。
RLVR在推理语言模型中的应用
RL数据集
DeepSeek-R1-Zero在推理任务中取得了优异表现,它在知识任务中也取得了优异表现,这是通过独立的RLVR流程实现的。高质量精选数据集在其RLVR过程中被使用,这是成功的关键。
因此 多项复制研究进行了探索 探索的内容是如何利用开源数据 以及如何利用强大模型 从而高效创建训练数据集的策略 。
这些数据集包含多种在R训练中能够被验证的任务,是主要聚焦于数学以及编程问题解决的数据集,表3给出了这些数据集的统计概览。

RL组件
DeepSeek发布了DeepSeek-R1-Zero和DeepSeek-R1,展示了成功经验,即通过强化学习(RL)微调语言模型(LLM)来应对复杂推理任务 。
相关研究基于精心挑选的训练数据,主要集中在配置RL框架的关键部分,目的是实现卓越性能,这包括采用高效的RL算法(如GRPO),还包括设计奖励机制。
表4提供了这些研究方法的比较。
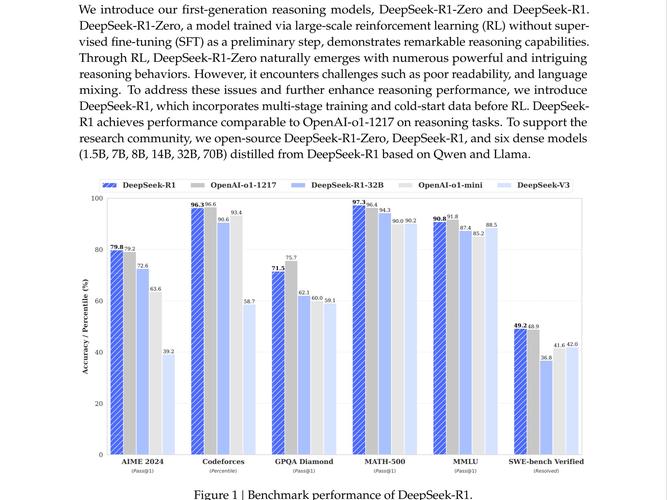
表4对多个竞争性开源DeepSeek - R1复制研究在强化学习验证任务(RLVR)中所使用的算法以及奖励设计方案进行了总结。为方便比较,DeepSeek - R1系列模型的相关信息被单独列了出来。
在基于结果与奖励的强化学习方法里,近端策略优化算法和广义近端策略优化算法,是微调大语言模型时最常被使用的算法。
有趣的是,近期有一些复制研究,这些研究对这些方法进行了各种改进,还针对特定目标优化了训练效果。
研究团队回顾了几种具有代表性的基于RL的大语言模型微调算法,其中有REINFORCE、PPO、GRPO以及它们的变体,另外,他们梳理了这些方法的改进情况以及改进背后的动机,目的是清晰概述基于结果 - 奖励的RL训练方法的技术进步。
奖励机制
奖励是RL训练的核心,它定义了优化的目标,它引导模型的行为。
一个奖励机制若设计良好,便能提供清晰的信号,还能提供一致的信号,进而帮助模型学习到有效的策略。
然而,奖励模型常常容易遭遇「奖励欺骗」,也就是模型通过钻空子获得高分而非真正解决问题,所以近期研究更倾向于使用基于规则的结果奖励系统。
这些系统通常分为三类:
采样策略
直观来说,在训练过程中合理选择样本对RL的有效性至关重要。
一方面,课程学习方法借助逐步加大任务难度这一方式,提高了复杂样本的利用率。另一方面,合理运用拒绝采样技术能够提升样本效率,还能使训练保持稳定。
RLVR在其他任务上的应用
借助RLVR,DeepSeek-R1的复杂推理能力得到显著提升,在复杂语境理解、问题解决等推理密集型任务方面取得成功。
RLVR让大模型可以在没有人工指导的情形下,借助可验证的答案来学习,进而执行任务,以此激发大模型的复杂推理能力。
受此启发,多项研究展开了探索,这些研究针对RLVR,探索其在不同任务中的复杂推理范式。
这些结果凸显了复杂推理语言模型的潜力,其通过RL训练策略,能够超越监督数据资源,甚至超越人类能力 。